Designing Data-Intensive Application - Transactions - 可串行化
May 11, 2019這是Designing Data-Intensive Application的第二部分第三章節的Part3: 可串行化
筆者註: 這個章節書中敘述的方式太過凌亂 對於初學者非常吃力 筆者改變了介紹的方式甚至例子都做了更改 在本部落格中將事務一章分為三篇文章
事務Part1 - ACID
事務Part2 - 弱隔離級別
事務Part3 - 可串行化
本篇是系列文的Part3
本文所有圖片或代碼來自於原書內容
您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
可串行化
我們在Part2討論了各種不同的隔離程度 跟各種隔離程度可能會發生的並發問題
| 隔離級別 | Dirty Write | Dirty Read | Non-repeatable read | Phantom read |
|---|---|---|---|---|
| None | O | O | O | O |
| Read Uncommited | X | O | O | O |
| Read Commited(Non-repeatable read) | X | X | O | O |
| Repeatable read | X | X | X | O |
| Serializable | X | X | X | X |
可串行化(Serializability)隔離通常被認為是最強的隔離級別 它保證即使事務可以並行執行 最終的結果也是一樣的 就好像它們沒有任何並發性問題一樣
換句話說 數據庫可以防止所有可能的競爭條件
目前大多數提供可串行化的數據庫都使用了三種技術之一:
1.就是真的一個一個執行
2.兩階段鎖(Two-phase locking)
3.可序列化的快照隔離(serializable snapshot isolation)
本文會一一介紹以上的技術
就是真的一個一個執行
避免並發問題的最簡單方法就是完全不要並發

如字面上所說 就是所有有可能動到同一個物件的事務 都一個一個執行 這個做法在以前是覺得可笑的 但最近卻又開始變得可行 原因如下
1.RAM越來越便宜 很多場合都已經可以把所有數據都存在內存中 當所有需要訪問的數據都在內存中時 事務處理的執行速度要比等待數據從磁盤加載時快得多
2.OLTP(事務處理)的操作通常都很直覺 只需要少量的讀寫操作 跟OLAP(分析系統)比起來非常快
Store procedure(儲存程序)
儲存程序 指的就是把事務的應用邏輯封裝在資料庫裡
回顧一下之前醫院醫生oncall的例子
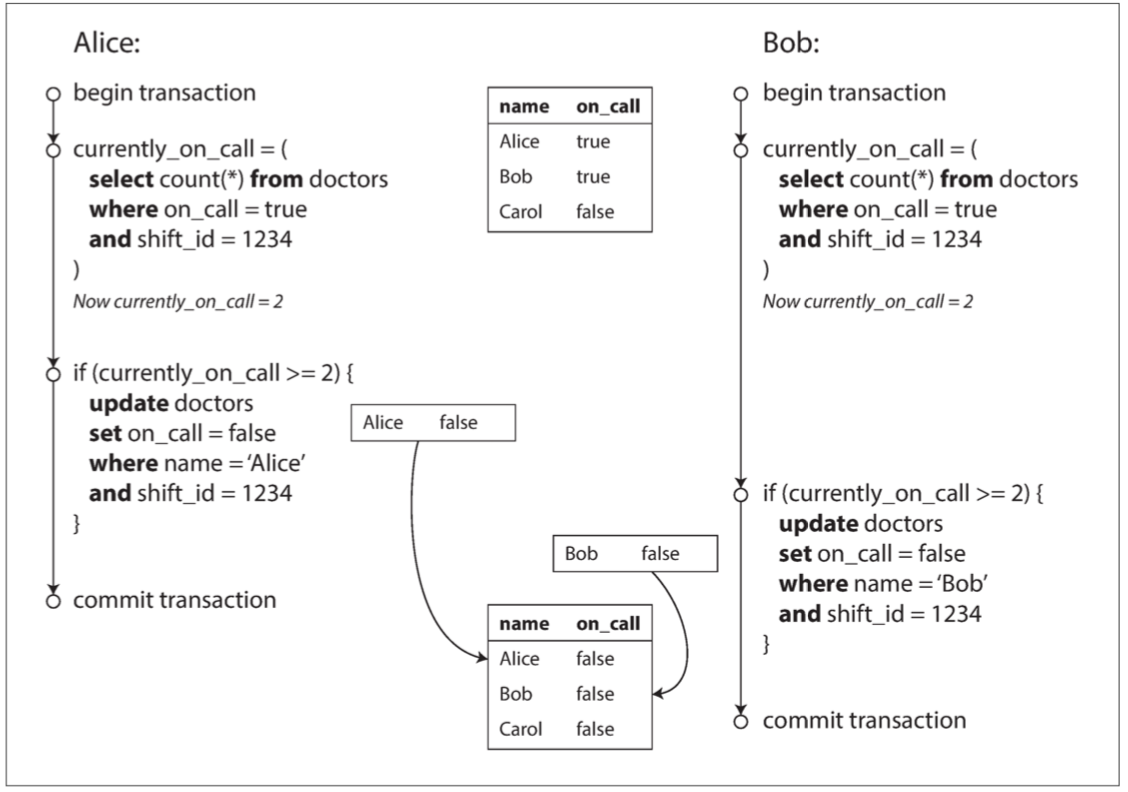
應用程式組裝了一個query 丟給資料庫執行 資料庫跑完回傳給應用程式看一下有沒有符合條件 有的話再組裝一個query丟給資料庫執行
如下圖的Interactive transaction
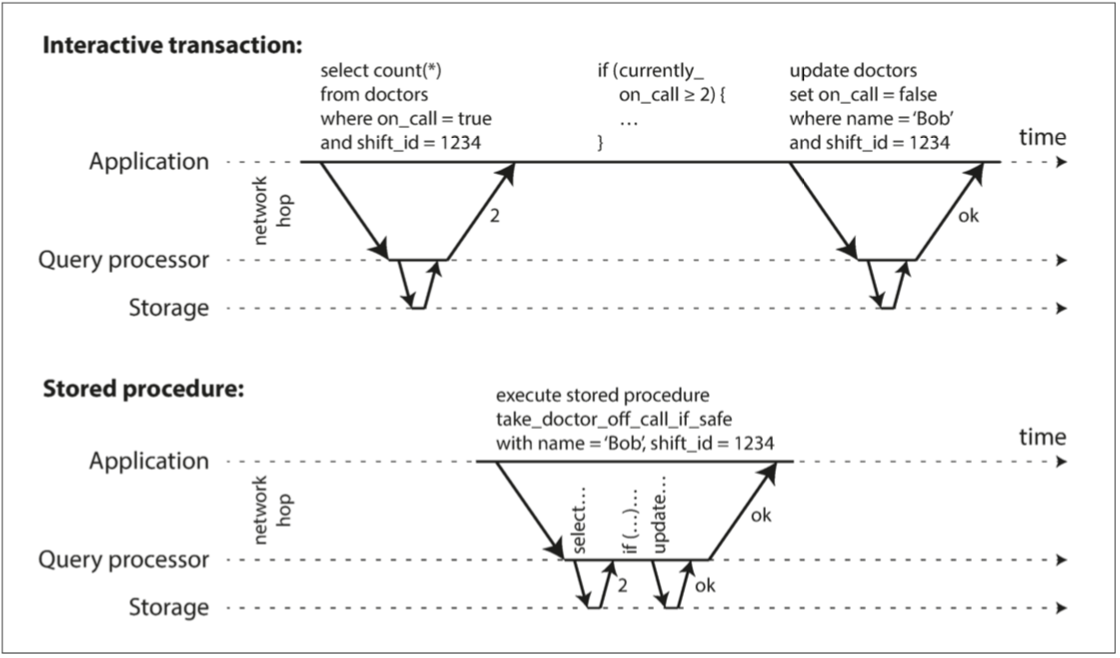
你看得出來 應用程序和數據庫之間的溝通耗費了大量的時間 如果我們不允許並發處理 而且一次只做一個事務 那吞吐量會相當悲劇 因為大部分的時間資料庫都在等應用程式發出下一個查詢
所以改進方式 就是儲存程序 我們把應用程式的邏輯直接告訴資料庫 讓他直接幫我們搞定 少了一次網路的傳輸
儲存程序優缺點
存儲過程在關係型數據庫中已經存在了一段時間了 從1999年以來它們一直是SQL標準的一部分 但基於某些原因 大家以前都不太喜歡用
1.每個數據庫都有自己的存儲過程語言(Oracle有PL/SQL, SQL Server有T-SQL, PostgreSQL有PL/pgSQL等等) 這些語言並沒有跟上通用編程語言的發展 所以從今天的角度看 語法都非常醜陋陳舊
2.和在應用程式中跑程式比起來 在數據庫跑程式管理起來比較困難 debug困難 版本控制困難以及部署困難
3.數據庫通常對於性能的要求比在應用程式高上許多 在數據庫中一個寫得不好的儲存程序 會比程序在應用程式中帶來更大的麻煩
如今這些問題已經慢慢的被克服 許多現代的存儲放棄了PL/SQL 使用現有的編程語言 (VoltDB使用Java或Groovy, Datomic使用Java或Clojure, Redis使用Lua)
分區
雖然一個一個執行讓事情變得簡單 但吞吐量的上限就是單機單核的速度 如果請求大部分都是讀請求 還有機會在不同的機器使用相同快照處理 但如果請求大部分都是寫請求 那單線程事務處理器可能成為一個嚴重的瓶頸
如果你要擴展到多個CPU核心和多個節點 可以對數據進行分區 如果你找到可以很好的分區的方法 讓每個事務可以在不同的區擁有自己的事務線程 這樣吞吐量就可以跟CPU數量呈現性發展
但只要有一個事務需要同時訪問兩個不同分區的物件 那就需要數據庫在觸及的所有分區之間協調事務 這可能某種程度需要同時鎖住需要被訪問的分區 而通常這協調的開銷非常大
事務是否可以是劃分至單個分區很大程度上取決於應用數據的結構 簡單的key-value數據通常可以非常容易地進行分區 但是具有多個二級索引的數據可能需要大量的跨分區協調(參閱分區和次級索引)
就是真的一個一個執行 總結
在特定約束條件下 真的一個一個執行事務 已經成為一種實現可序列化隔離等級的可行辦法
1.每個事務都必須小而快 只要有一個緩慢的事務 就會拖慢所有事務處理
2.通常很常被訪問的數據放進內存 不常被訪問的放進硬碟 所以如果事務需要訪問那些在硬碟裡的資料 就會變得非常慢
3.寫入吞吐量必須低到能在單個CPU核上處理 不然事務需要能劃分至單個分區 而且不需要跨分區協調
4.跨分區事務是可能的 但是它們的使用程度有很大的限制
兩階段鎖定(2PL)
大約30年來 在數據庫中只有一種廣泛使用的串行化算法 就是二階段鎖定 two-phase locking
注意: 2PL(2-phase locking) 不等於 2PC(2-phase commit) 它們是完全不同的東西
之前我們看到鎖通常用於防止髒寫: 如果兩個事務同時嘗試寫入同一個對象 則鎖可確保第二個寫入必須等到第一個寫入完成事務(中止或提交)之後才能繼續
兩階段鎖定也很類似 但是卻更強 只要沒有寫入 就允許多個事務同時讀取同一個對象 但對象只要有寫入(修改或刪除) 就需要獨佔訪問(exclusive access)權限:
1.如果事務A讀取了一個對象 並且事務B想要寫入該對象 那麼B必須等到A提交或中止才能繼續
2.如果事務A寫入了一個對象 並且事務B想要讀取該對象 那麼B必須等到A提交或中止才能繼續
在2PL中 寫需求不僅會阻塞其他寫需求 也會阻塞讀需求 但讀需求只會阻塞其他寫需求
相比於快照隔離(讀不阻塞寫 寫也不阻塞讀) 2PL在讀寫會互相阻擋的前提下 我們避免了不可重複讀問題
實現2PL
讀與寫的阻塞是通過為數據庫中每個對象添加鎖來實現的 鎖可以處於共享模式(shared mode)或獨佔模式(exclusive mode) 實現方式如下:
1.如果事務要讀取一個對象 必須先以共享模式獲取鎖 共享鎖可以同時讓很多事務同時持有 但如果有一個事務已經在相同對象上持有排它鎖 則其他事務必須等待
2.若事務要寫入一個對象 它必須首先以獨佔模式獲取該鎖 其他人都不能再拿相同事務的共享鎖或是排他鎖 當然如果對象的鎖已經被拿走(不論是共享鎖或是排他鎖) 這個想寫的事務就必須等
3.如果事務需要先讀取再寫入對象 則它可能會將其共享鎖升級為獨佔鎖 升級鎖的工作與直接獲得排他鎖相同
4.事務獲得鎖之後 必須繼續持有鎖直到事務結束(提交或中止)
這就是為什麼這叫做兩階段鎖 第一階段(當事務正在執行時)獲取鎖,第二階段(在事務結束時)釋放所有的鎖
由於使用了這麼多的鎖 因此很可能會發生一種情況 事務A等待事務B釋放它的鎖 而且事務B等待事務A釋放它的鎖 這種情況叫做死鎖 現在大部分的數據庫會自動檢測事務之間的死鎖 並由應用程式重試
2PL的性能
可想而知 2PL最大的缺點就是性能問題 兩階段鎖下的事務吞吐量與查詢響應時間要比弱隔離級別下要差得多
主要原因是獲取跟釋放鎖的開銷很大 基本上你想要寫一個對象 你要先等其他也在這個對象做事的事務結束
而且運行2PL的數據庫可能具有相當不穩定的延遲 特別是P95, P99的延遲通常特別高 你只需要一個緩慢的事務或是存取大量數據的事務 就可以把系統的其他部分拖慢
最後 2PL的隔離級別中 死鎖會發生的很頻繁 解死鎖也需要開銷
在此之前我們講的鎖 都是普通鎖 也就是只針對單一個明確對象的共享鎖或是排他鎖 而Predicate lock 則是符合某些條件的所有物件的鎖
Predicate locks
該辦正事了 我們一直還沒處理幻讀的問題: 一個事務改變另一個事務的搜索查詢的結果 我們也知道一個具有可串行化隔離級別的數據庫必須防止幻讀
當我們要預訂一個會議室的時候 如果一個事務在某個時間窗口內搜索了一個房間的現有預訂 另一個事務不能同時插入或更新同一時間窗口與同一房間的另一個預訂
要實現這一點 我們需要Predicate lock 它類似於前面描述的共享/排它鎖 但是不屬於特定的對象 他符合所有符合某些搜索條件的對象
看個例子
SELECT * FROM bookings
WHERE room_id = 123 AND
end_time > '2018-01-01 12:00' AND
start_time < '2018-01-01 13:00';再說一次 一個Predicate lock會限制訪問所有符合某些搜索條件的對象
1.如果事務A想要讀取匹配某些條件的對象(就像在這個SELECT查詢中那樣) 它必須獲取查詢條件上的所有物件的Predicate lock 如果另一個事務B持有任何滿足這一查詢條件對象的排它鎖 那麼A必須等到B釋放它的鎖之後才允許進行查詢
2.如果事務B想要插入,更新或刪除任何對象 必須首先檢查是否有任何現有的Predicate lock匹配你目前想寫的對象 如果A正在執行以上的SELECT 那B也不能寫 必須等到A釋放鎖
關鍵的地方是 當A在查詢時獲取的符合條件的Predicate lock的物件中 包含還沒被創建的物件 當B想創個物件 符合了某個條件 我還不給你創建 因為有人正在拿Predicate lock
當我已經隔離到這種程度後 我才真正避免了幻讀(寫偏差)
索引範圍鎖 Index-range locks
奇怪 我們連幻讀都處理好了 為什麼2PL還沒結束呢??
答對了 因為Predicate lock性能太高 如果一個很活躍的事務持有很多Predicate lock 那其他人要檢查匹配的時候非常花時間 所以我們有一個近似的解法 稱為索引範圍鎖
剛剛我們的Predicate lock的條件是
1.room_id = 123
2.end_time > '2018-01-01 12:00'
3.start_time < '2018-01-01 13:00'
所以當事務B想寫入的時候 我們要判斷我們現在寫入的對象是不是符合1,2,3 符合的話就要等
但我們其實不用把這個條件抓得那麼緊 只要其中一個條件符合 我就讓你等 這樣我們就不用去跑一堆query看看我現在要寫的物件有沒有符合任何一個別人正在拿著的Predicate lock
那這三個條件要選哪個條件呢? 沒錯 選有index的那個條件 這樣判斷就快了
假設這個會議室的數據庫索引在room_id 那我們用索引範圍鎖改進之後 事務B只需要確認 room_id = 123 的鎖有沒有被拿走 優點就是因為有索引 所以可以很快知道鎖在不在 缺點就是其他事務可能是預定不同時間不同日期 但你還是把事務B給擋住
這個可以接受 因為
一個數據庫需要查詢有沒有別人拿著Predicate Lock的頻率(幾乎是所有的寫需求)
比起
真的有別人拿了索引範圍鎖的頻率(兩個不同事務對同一個room_id有興趣)
要多得太多了
所以這個trade-off完全可以接受
串行化快照隔離 Serializable Snapshot Isolation
魔王來了
再來總複習一下 我們在弱隔離級別中看到各種競爭條件(髒讀髒寫 不可重複讀和幻讀) 在強隔離級別中 看到了性能不好(2PL)跟擴展性不好(串行執行)的可串行級別 難道沒有一個更好的解嗎
的確是有一個很有前途的解法 叫做串行化快照隔離(SSI, serializable snapshot isolation)
悲觀鎖和樂觀鎖
要講到串行化快照隔離之前 我們先來講講什麼是悲觀鎖和樂觀鎖
剛剛提的兩階段鎖 其實是所謂的悲觀並發控制機制 原則就是 如果有事情可能出錯 那就最好等到情況安全後再做任何事情
你也可以說 就是真的一個一個執行 就是一個極度悲觀的作法 畢竟我們在當有一個事務在進行的時候就鎖住整個數據庫

相比之下 串行化快照隔離就是一個樂觀的並發控制技術 樂觀的原則是: 即使我知道有存在潛在的危險 我也不阻止事務讓它繼續執行 當真的需要提交的時候 我再看看有沒有什麼不好的事情發生 真的有發生再說
講到這邊 你應該就了解串行化快照隔離是什麼意思了 就是基於基本的快照隔離之上(也就是事務中的所有讀取都是來自數據庫的一致性快照) 然後在提交之前利用算法來看看這個事務該終止還是寫入
處理幻讀
為什麼在寫入前多跑一個算法來檢查就可以知道該不該寫入呢 記不記得我們之前提到幻讀的原因是基於過時前提的決策: 事務從數據庫讀取一些數據(拿出所有oncall的醫生) 檢查查詢的結果(看有幾個oncall) 並根據它看到的結果決定採取一些操作
如果只是單純的快照隔離 可能原始查詢的結果在事務提交時可能不再是最新的 因為數據可能在同一時間被修改 換句話說 事務基於一個前提(有兩個以上oncall醫生)而行動 但是當你事務要提交時 前提(只剩一個oncall醫生)已經不成立了
當應用程序進行查詢時(看有幾個oncall) 數據庫不可能知道應用程序如何使用該查詢結果 數據庫能做的就是假設

假設什麼? 假設任何對該查詢的結果的變更都可能會使該事務中的寫入變得無效 也就是數據庫必須要知道這個事務的寫入是基於過時的前提之下做的操作 然後把這個事務中止
數據庫要怎麼知道查詢結果是否可能已經改變了呢? 有兩種情況要考慮
1.檢測對舊MVCC(多版本並發控制)對象版本的讀取(讀之前存在未提交的寫入)
2.檢測影響先前讀取的寫入(讀之後發生寫入)
檢測舊MVCC讀取
複習一下 快照隔離通常是使用MVCC來實作 當一個事務從MVCC數據庫中的一致快照讀時 它將忽略取快照時尚未提交的任何其他事務所做的寫入 可是我們現在需要偵測這種情況
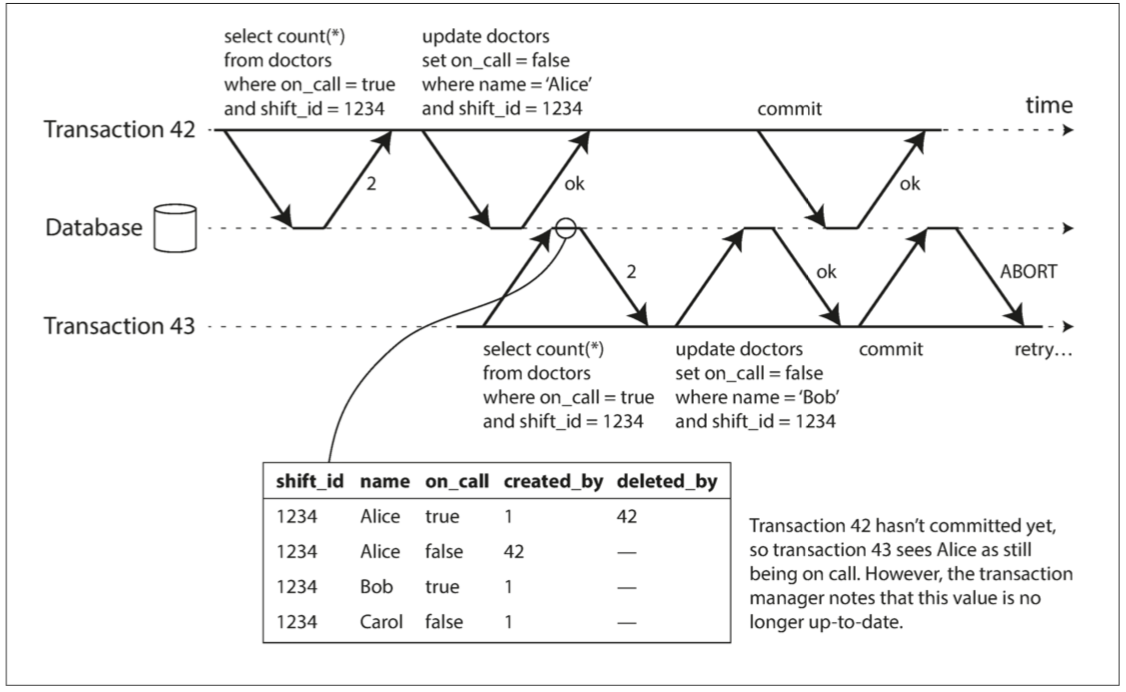
事務43認為Alice的oncall = true(因為事務42還沒被提交) 然而在事務43被提交的時候事務42已經提交完了 所以事務43的前提已經不為真 應該要中止
數據庫怎麼做到這件事呢 他就需要記錄上圖的下方那張表 數據庫就知道 我給事務43的回答是因為42還沒提交 等到42提交後 43就不給寫了
那你會覺得奇怪 那為什麼要浪費時間等到43提交呢 當你發現42很可能會改變43的前提時 就中止43就好啦 答案是 因為數據庫並不知道43要幹嘛 43可能只是想要讀根本沒有要寫 或者是43提交的時候42也還沒提交 那我們也不該終止43
透過樂觀的避免了不必要的中止 我們還長期的支持讀需求
檢測影響之前讀取的寫入
第二種情況要考慮的是另一個事務在讀取數據之後修改數據
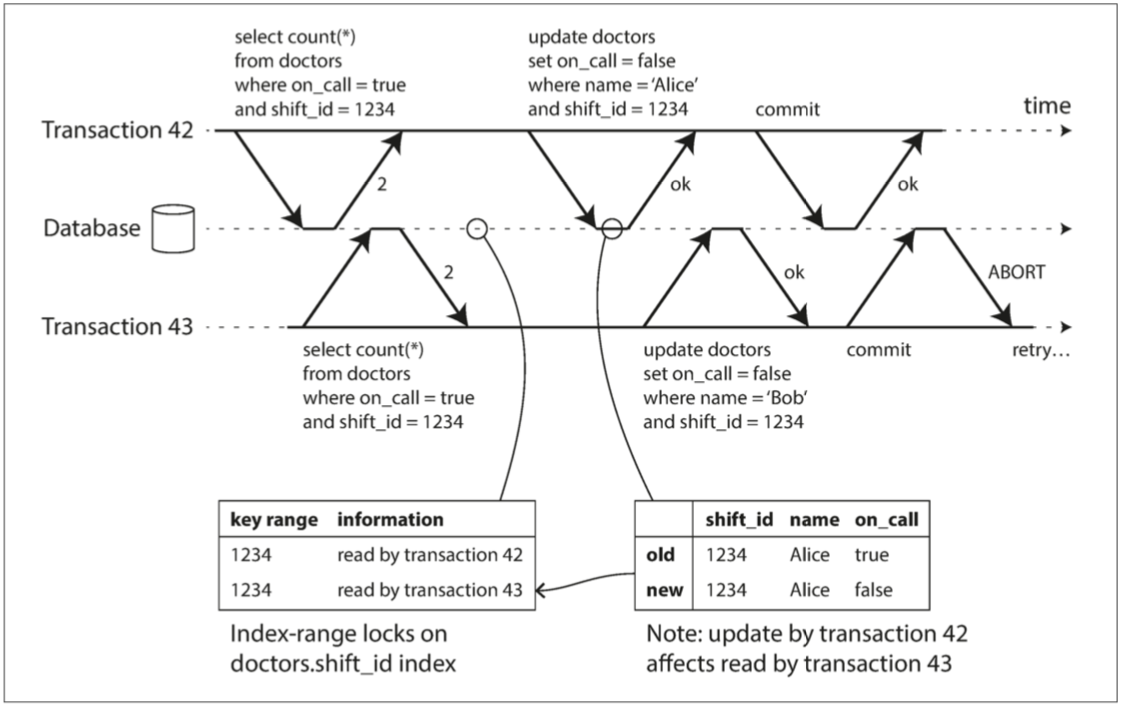
上圖中 事務42和43都在班次1234查找oncall醫生(數據庫可以使用索引項1234 來記錄事務42 和43 讀取這個數據的事實)
當事務寫入數據庫時 數據庫必須在索引中查找最近曾讀取受影響數據的其他事務 然後一一通知
在這個例子 事務42首先提交成功 雖然事務43有改動事務42查詢的內容 但是事務43還沒提交所以不算數 而42提交的時候就會跟數據庫打小報告 說老師我贏了 所以等等43提交的時候不能讓他過 所以之後43的提交(因為有寫的改動)被中止
可序列化的快照隔離的性能
與兩階段鎖定相比 可序列化快照隔離的最大優點是一個事務不需要阻塞等待另一個事務所持有的鎖 有著就像在快照隔離下一樣的優勢 – 寫不會阻塞讀 讀不會阻塞寫
這種設計使得查詢延遲更可預測 而且讀查詢可以運行在一致的快照上 對於讀取繁重的工作負載非常有吸引力
事務的中止率顯著影響SSI的表現 比如 長時間讀取和寫入數據的事務很可能會發生衝突並中止 所以可以的話 最好讀寫事務都盡量短
總結
只有可串行化的隔離才能防範所有並發問題 我們討論了實現可序列化事務的三種不同方法
1.就是真的一個一個執行: 如果每個事務執行得很快而且吞吐量足夠低 這是個好選擇
2.兩階段鎖: 實現可序列化的標準方式 但是性能差
3.可序列化的快照隔離: 它使用樂觀的方法 允許事務執行而無需阻塞彼此 當一個事務想要提交時 它會進行檢查 如果執行不可串行化 事務就會被中止