Designing Data-Intensive Application - Partitioning
March 12, 2019這是Designing Data-Intensive Application的第二部分第二章節: 分區
本文所有圖片或代碼來自於原書內容
您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
分區
我們在第五章討論了複製 指的是數據在不同節點上的副本 但如果數據本身就很大 無法單獨存在一個節點 我們還要把數據進行分區(partitioning)又稱分片(sharding)
術語
在MongoDB, ElasticSearch和Solr Cloud稱為shard 在HBase中稱為Region 在Cassandra和Riak中稱為vnode 在Couchbase稱為vBucket 但約定俗成的說法就是Partitioning
通常情況下 每條數據屬於且僅屬於一個分區 有很多方法可以實現這點 本章會進行深入討論 實際上 每個分區都是自己的小型資料庫
分區的主要目的是可擴展性(scalability) 對於單個分區上的Query 每個節點可以單獨執行 所以可以輕易藉由增加節點來擴大吞吐量(當然有些複雜一點的查詢可能會需要跨越節點處理)
這一章我們會先介紹分割大型數據的不同方法 並觀察索引如何和分區配合 然後會討論如何平衡分區(如果你想要添加或移除節點) 最後則是討論數據庫如何把請求route到正確的分區來執行查詢
分區與複製
分區通常與複製一起使用 意思就是你分完區之後 每個分區的數據也都同時備份到好幾個節點上 增加容錯能力
既然知道一個節點可以存儲多個分區 那在使用主從模型的前提下 每個節點可以有一個領導者分區跟若干追隨者分區
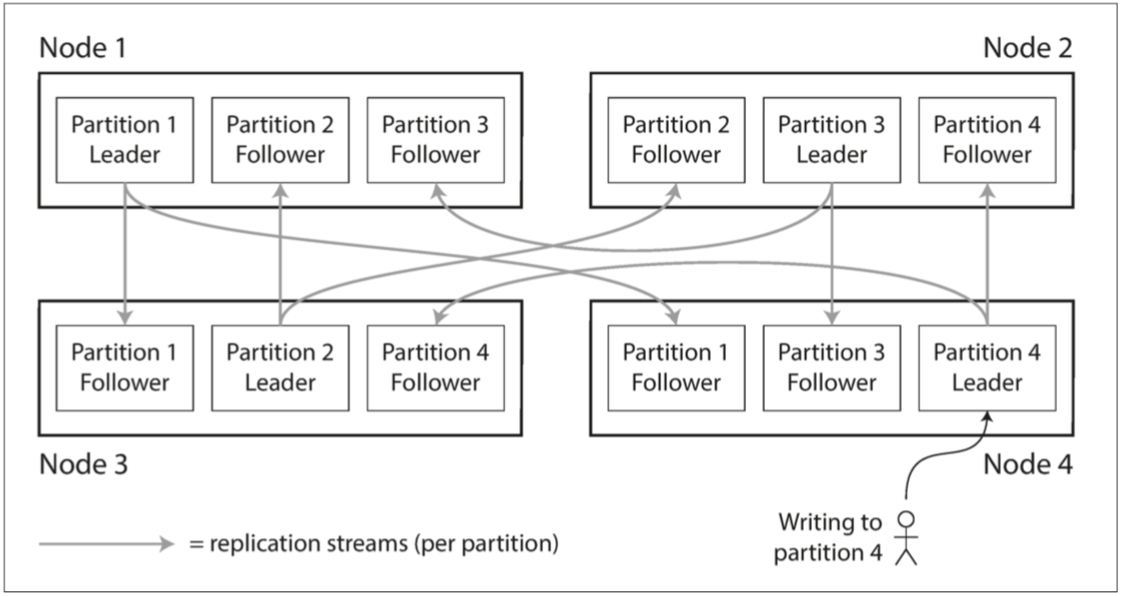
上圖的例子 你可以想成 我先把資料分區分成四個部分 Node1拿第一個部分 Node3拿第二部分 Node2拿第三部分 Node4拿第四部分 然後再進行複製 把第一部分分區分給Node3, Node4進行複製 第二部分分區分給Node1, Node3進行複製… 依此類推
這樣的配置即使你真的天選的衰 同時有兩個Node掛掉 你還是可以把你的資料救回來
複製的選擇跟分區的選擇沒有太大相關(你想怎麼分區跟你想複製幾份沒有太大關聯) 為了討論簡單起見 本章先不考慮複製的問題
鍵值數據的分區 Partition of Key-Value Data
來實際討論該怎麼分區 我們希望分區能達成的目的是
數據和查詢負載均勻分佈在各個節點上
如果每個節點公平分享data跟traffic 那你有十倍的節點應該可以增加十倍的吞吐(不考慮複製) 所以如果分區分的不公平 某些分區有著比較多的data或traffic 我們稱為偏斜(skew) 偏斜的分區會導致效率下降 而高負載的分區稱為熱點(hot spot)
避免熱點的簡單方式就是讓數據隨機分配給不同節點 這樣保證數據平均分配 但當你查詢時 你就得每個節點都查詢
當然我們有些更好的方法
根據key的range分區
一種分區的簡單方法 就是為每個分區指定一段連續的key的範圍 下圖是百科全書的分區
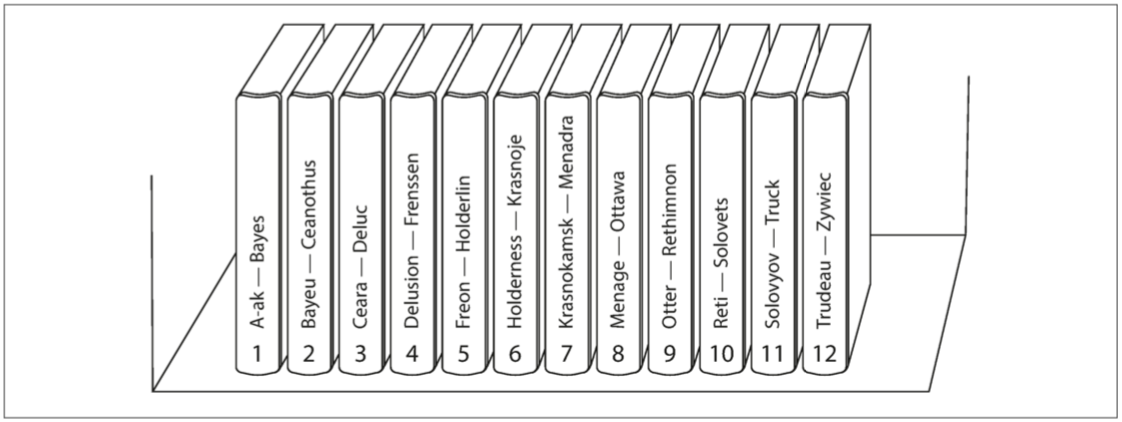
你想要找Beautiful就知道是在第二區 想找jyt0532就是在第六區
注意因為key的範圍並不是均勻分布 所以數據分布的也不均勻 因為每個字母開頭的單字不一樣多 所以如果只是簡單的規定每兩個字母一區 很容易會出現偏斜 為了平均分配 分區的邊界需要進行調整 (比如上圖A-B在第一區 可是T-Z是在最後一區)
至於在每個分區中 我們可以按照順序來存儲key(參閱SSTables和LSM-樹) 好處是進行範圍掃描非常簡單 你也可以把key接起來當作連接索引處理(參閱多列索引) 你就可以一個查詢得到多筆數據
比如說我們的數據是有關網路感測器的數據 primary key是測量的時間(year-month-day-hour-minute-second) 那範圍掃描就很好用 我們可以輕鬆獲取每個月的所有數據
但是key range的分區缺點也很明顯 就是某些特定的訪問模式會產生熱點 剛剛的例子 primary key是時間戳 那不幸的是 每日的寫入都在同一個分區 這樣就會造成某一個節點過載 其他節點空閒
為了避免這個問題 我們還得加上除了時間戳以外的其他東西作為primary key
比如時間戳前加上sensor名稱 這樣primary-key變成
sensorName-year-month-day-hour-minute-second
這樣不同的感測器同時寫入 最終就會平均的分佈在不同節點
但當你想要獲取一個時間內所有的感測器的資料 你就得要每個節點都下一樣的範圍查詢
按照Key的Hash分區
因為偏斜和熱點的風險 使得許多分布式數據存儲都使用hash來決定一個key的分區
一個好的hash function可以讓數據平均分佈 因為hash function的目的只是用來分區 所以其實我們不需要用到太強的hash演算法(MD5就差不多夠用了) 當你定義好了hash function 你就可以為每個分區分配一個hash範圍(不是key的範圍)

缺點也很明顯 我們失去了對於key的範圍搜索的能力 曾經相鄰的主鍵被分散在不同的分區中
MongoDB裡面 如果使用了這個方法 那所有範圍搜索都必須發送到所有分區
Riak, Couchbase, Voldemort則不支持主鍵上的範圍查詢
Cassandra則是採取折衷的策略 Cassandra中的表可以使用由多個列組成的復合主鍵(compound primary key) key裡面的第一個列拿來hash 其他列用來當作SSTable中排列的連接索引 雖然查詢無法在復合主鍵的第一列中做範圍查詢 但如果第一列已經被指定固定值 其他列就可以做範圍查詢
Cassandra的連接索引也為一對多數據提供了一個優雅的數據模型 比如說一個社交網站 一個用戶會發布很多更新
如果更新的主鍵被選擇是(user_id, update_timestamp) 那麼你可以有效的查詢一個特定用戶的一定範圍內的更新 因為每個用戶存在不同分區 每個分區內可以做範圍查詢
負載傾斜與消除熱點
雖然由hash分區可以減少熱點 但還是無法完全避免 畢竟大多數情況下 所有的讀寫操作都是針對同一個key 所有的請求都會被route到同一個分區
比如常見的例子是一個社交名人發了一篇文章 這個事件會導致大量的寫入到同一個key 這還是很可能導致負載爆掉 常見的解決辦法是讓應用程式primary key的結尾加一個隨機數 當你加的是兩個位數的十進位數 就可以把主鍵分成100個不同的分區
那當然也有缺點 就是你的讀取就比較痛苦了 你必須把100個分區的數據合併 所以你需要其他分法來追蹤哪些鍵需要被分割和怎麼分割
分區和次級索引(Partitioning and Secondary indexes)
目前為止的討論方案都是依賴於key-value模型 如果只透過key來訪問紀錄 我們可以從key來決定分區 並且將請求導到相對應的分區來處理
但如果涉及secondary index 情況就會變得複雜 次級索引的問題是他們不能整齊的映射到分區 所以有兩種針對二級索引數據進行分區的方法
1.基於文檔的(document-bases)分區
2.基於關鍵詞(term-based)的分區
由文檔來分區二級索引
假設你正在經營一個賣車的網站 每個記錄都有一個文檔id 並用文檔id對數據進行分區(分區0分配id 0-499 分區1分配id 500-999等等)
你想讓用戶搜索汽車 並讓他們由顏色或是廠商來過濾 那你就必須在顏色和廠商上面創造二級索引
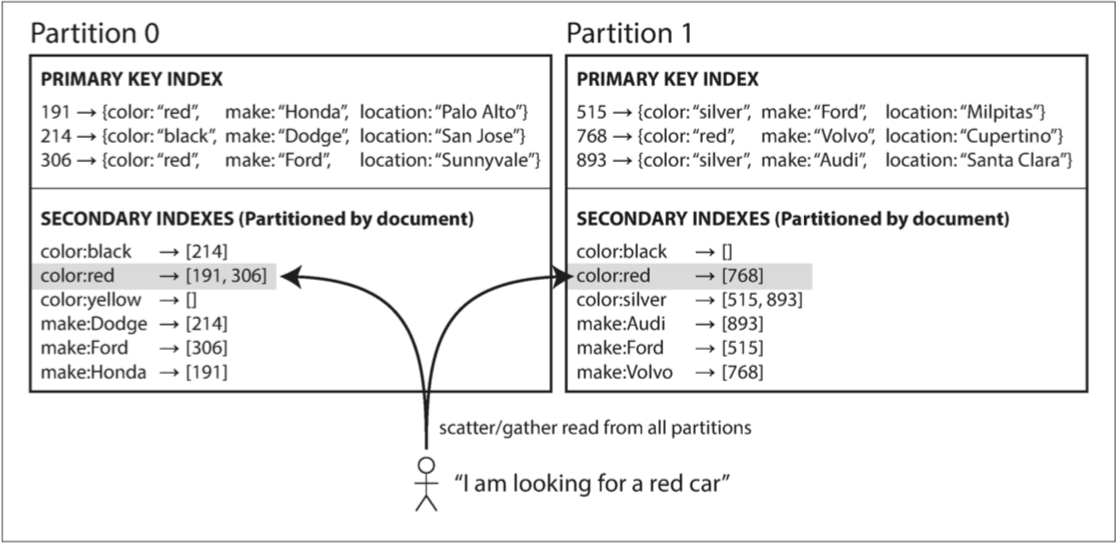
你每在一個分區中加入一個新的記錄 這記錄也都會更新你的二級索引表 那你下次就可以知道分區二中紅色的車只有768這台
這種索引方法中 每個分區是完全獨立的 每個分區維護自己的二級索引 不在乎其他人的二級索引 所以文檔分區索引又稱為本地索引(local index)
要注意的是 當你要找所有紅色的車 你還是必須對每一個分區都下一樣的查詢 這種查詢分區數據庫的方法稱為scatter/gather 並且會讓二級索引的查詢非常昂貴 即使你平行的對每個分區都進行一樣的查詢 scatter/gather會導致尾部延遲放大 但這個方法卻被廣泛使用 MongoDB, Riak, Cassandra, ElasticSearch, SolrCloud和VoltDB都使用文檔分區進行二級索引
通常你的數據庫會建議你建構一個可以剛好從一個分區提供二級索引的方案 比如說紅色車都在分區1 藍色車都在分區2 但這通常不可行 特別是你需要提供不同的二級索引需求(比如顏色跟廠商)
由關鍵詞來分區二級索引
相對於每個分區擁有一個自己的二級索引 我們也可以創建一個全局索引 這個全局索引包含了所有分區的所有數據的索引 但是我們不能只把這個索引存在單獨一個節點上 因為這可能會讓那個節點成為bottleneck(同時分區也失去意義)
所以全局索引也要進行分區
直上例子
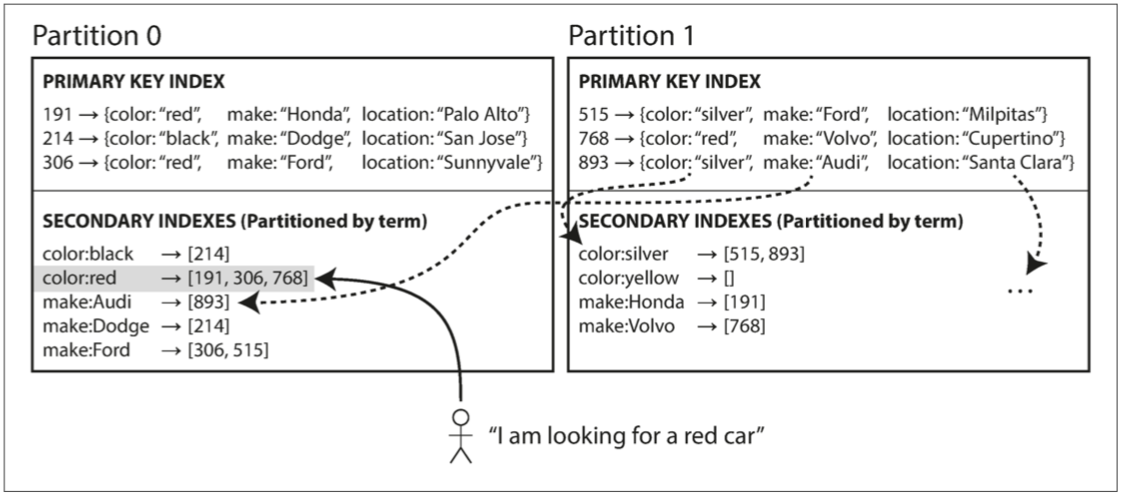
所有紅色的車都存在紅色索引中 而紅色索引本身也被分區到Partition0(color索引開頭a-r在partition0 s-z在partition1 廠商索引a-f在partition0 廠商索引g-z在partition1)
我們稱這種索引稱為關鍵詞分區(term-partitioned) 因為我們尋找的關鍵詞決定了索引的分區方式
更厲害的是 關鍵詞的分區 跟 主鍵的分區 方式不用一樣 你主鍵分區可以用hash 關鍵詞分區可以直接照term分區 或是hash過再分區 你可以自己比較優劣
比如你二級索引有價格的話 那你直接照價格(term)分區 還可以輕鬆的提供範圍查詢 但如果你想要平均的分佈traffic 你也可以把關鍵詞Hash過後再分區
關鍵詞分區的全局索引優於文檔分區索引的地方當然就是查詢的效率問題 不需要scatter/gather 客戶只需要向包含關鍵詞的分區發出請求 當然缺點就是寫入比較慢而且複雜 因為你寫入單個文檔可能會影響索引的多個分區 比如你這台車的顏色紅色索引存在分區1 這台車的廠商索引存在分區2 等等
理想情況下 索引總是最新的 寫入數據庫的每個文檔都會立即反映在索引中 但關鍵詞分區的全局索引就比較複雜 需要跨分區的分佈式transaction 並不是所有數據庫都支持
實際情況下 對全局二級索引的更新通常是異步(asynchronous)的 意思就是如果在寫入之後很快就讀取 很可能會讀不到
Amazon DynamoDB聲稱在正常情況下二級索引會在不到一秒的時間內更新 但在infrastructure有故障的時候會有延遲
全局關鍵詞分區索引還有其他用途 比如說Riak的搜索功能和Oracle的數據倉庫
分區再平衡
我們也不是確定怎麼分區之後就天下太平 隨著時間進行 數據庫會有些變化
1.查詢吞吐量增加
2.數據增加
3.舊機器故障
這些需求的更改 需要我們把數據跟請求從舊節點轉到新節點 這過程稱為再平衡(rebalancing)
再平衡的要求如下
1.再平衡之後 負載(數據存儲/讀取請求/寫入請求)應該在節點之間公平地共享
2.再平衡發生時 能夠繼續接受讀取和寫入
3.節點之間只移動必須的數據 以達到快速平衡
平衡策略
有很多不同的平衡方法 我們一個一個來看看
Hash mod N
第一個方法 就是把key給Hash 然後平均分成N等分
比如說hash(key) % N 就可以平均的保證N等分 但這個方法的問題是當今天要多加一個節點或是少一個節點 hash(key) % (N+1) 大多數的資料跟請求都會都會換節點
我們想要一個只移動必須數據的方法
固定數量的分區
我們也可以 創造比節點數目還多的partiion 每個節點分配若干partition 比如我有10個節點 我刻意分配成1000個partition 每個節點負責100個partition
如果有新的節點加入 他就從目前的每個節點中偷幾個partition 直到再次公平分配
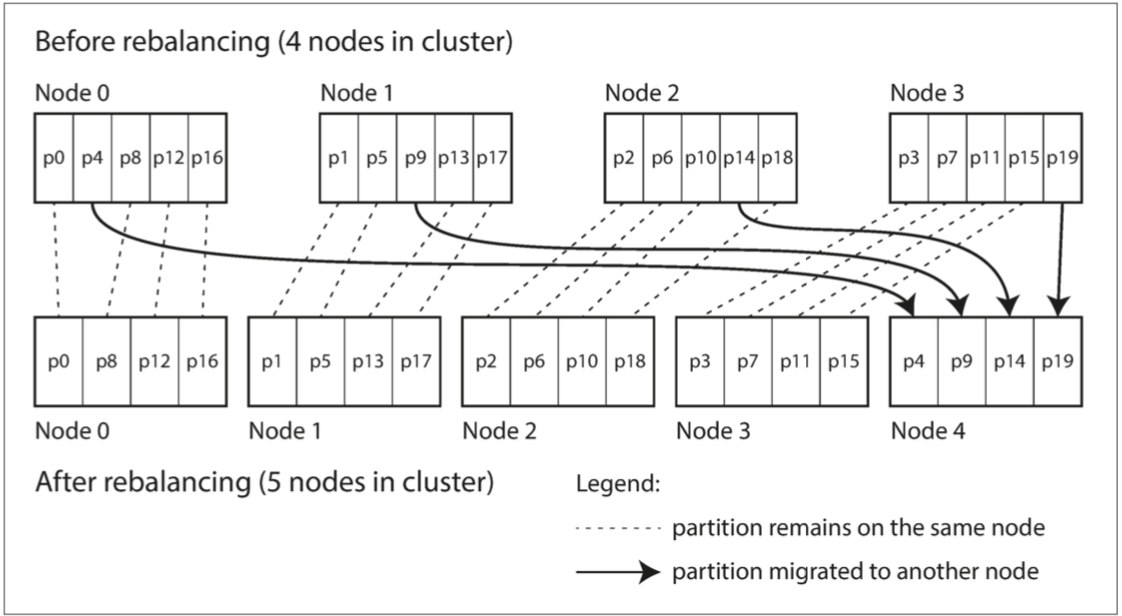
這種配置中 分區的數量通常在數據庫第一次建立時確定 分區的數量就是你最大的節點數目 所以你必須選擇足夠多的分區來適應未來的增長
如果數據的總大小很難預估(比如一開始很小 後面增長很快) 那選擇正確的分區數目很困難 由於每個分區包含了總數據固定比例的數據 所以每個分區的大小 隨著總數據量線性成長 如果每個分區都很大 再平衡就會變得很昂貴 如果每個分區都很小 那你要移動很多個分區 開銷也會很大 只有在每個partition的大小剛剛好的時候 才會有很好的性能
所以如果分區數量固定 但數據變動很大 這個方法難以達到好性能
動態分區
使用key-range分區的數據庫 手動配置邊界非常的煩瑣 所以通常會使用動態分區 比如HBase和RethinkDB 當partition增長到超過配置的大小(HBase預設10G) 會被分成兩個partition 各負責一半 反之 如果很多數據被刪除 partition大小變小了 那也可以把相鄰的partition合併
跟固定數量的分區一樣 每個partition分配一個節點 每個節點很多partition 當把大分區拆分之後 就可以把其中一半轉到其他節點 來平衡負載
動態分區的優點 就是分區的數量可以隨著總數據量變化 如果數據很少 那分區也不用太多 每個分區的大小都有一個可以被配置的最大值
按節點比例分區
剛剛講了兩個分區
1.固定數量的分區: 每個分區的大小和總數據量成正比
2.動態分區: 分區的數量和總數據大小成正比 藉由拆分和合併 來讓每個分區的大小維持在可配置的最大值跟最小值之間
這兩個分區方法 分區的數量和節點的數量都沒有相關
Cassandra和Ketama使用的第三種方法是使分區數與節點數成正比 也就是說 每個節點具有固定數量的partition
每個partition的大小隨著數據等比例增長 而節點數量保持不變 當你覺得需要增加節點數時 每個分區再次變小 因為通常你想加節點的時候都是因為數據變大 所以長久下來 每個分區的大小就比較穩定
而想加節點時需要做什麼呢 這個方法隨機的選擇現有的若干partition 把這些partition分兩份 拿走其中一份 這個隨機的因素可能會導致不公平的分割 但當你的分區數目一多 新節點最終會獲得公平的負載
運維:手動還是自動平衡
關於再平衡有一個重要的問題 應該自動還是手動
自動平衡: 系統自動決定何時將分區從一個節點移動到另一個節點
手動平衡: 管理員明確配置哪個分區給哪個節點 僅在管理員明確重新配置時才會更改
自動平衡當然方便 但是比較不可預測 因為再平衡是個很昂貴的操作 需要它重新移動數據和請求 如果這沒有做好 可能會使網路或節點負載過重 降低其他請求的性能
而且自動化與自動故障檢測的結合很能會很危險 比如說某一個節點過載(對於請求的響應很慢) 其他節點認為這個節點掛了 於是重新平衡 這個重新平衡會使得原本已經超過負荷的節點和其他節點都造成額外負擔 並讓情況變得更糟
因為這個原因 再平衡的過程中有人參與是一件好事 比完全自動的過程慢 但可以幫助防止運維意外
請求路由 Request Routing
我們已經知道了數據怎麼被分區到不同機器上 那當有個請求來的時候 應用程式要怎麼知道資料存在哪呢?
簡單來說 有幾種不同的方案
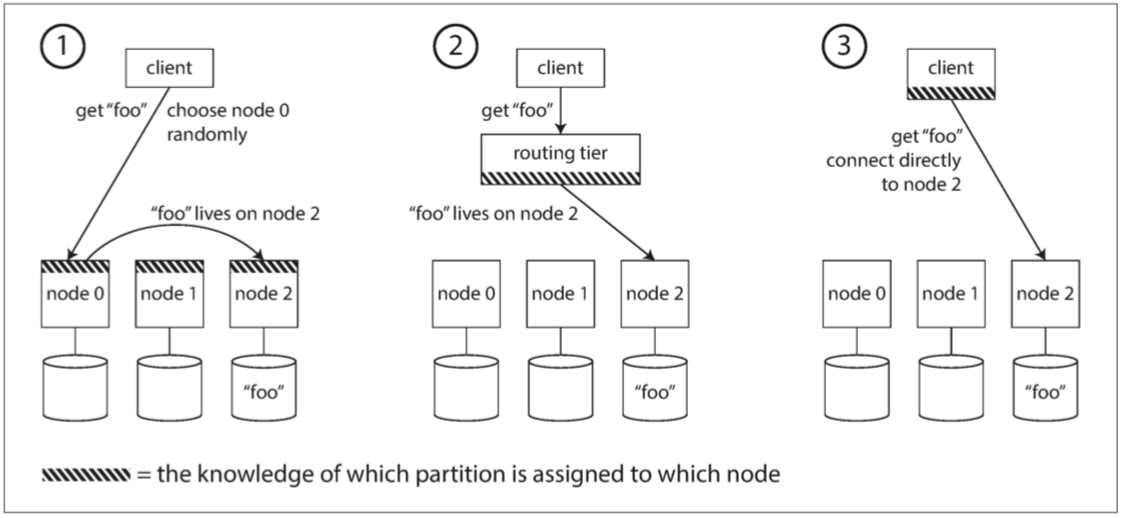
1.客戶可以發請求到任一節點(比如說Round Robin分配) 如果那個節點剛好有資料那很好 如果沒有 那再把請求轉到適當節點
2.把所有客戶端請求導到一個路由層 這一層決定這個請求要去哪個節點找數據
3.要求客戶端知道分區和節點的分配 讓客戶搞定要呼叫誰
Zookeeper
許多分佈式數據系統都依賴於一個獨立的協調服務 - Zookeeper 來追蹤一個集群每個節點的metadata
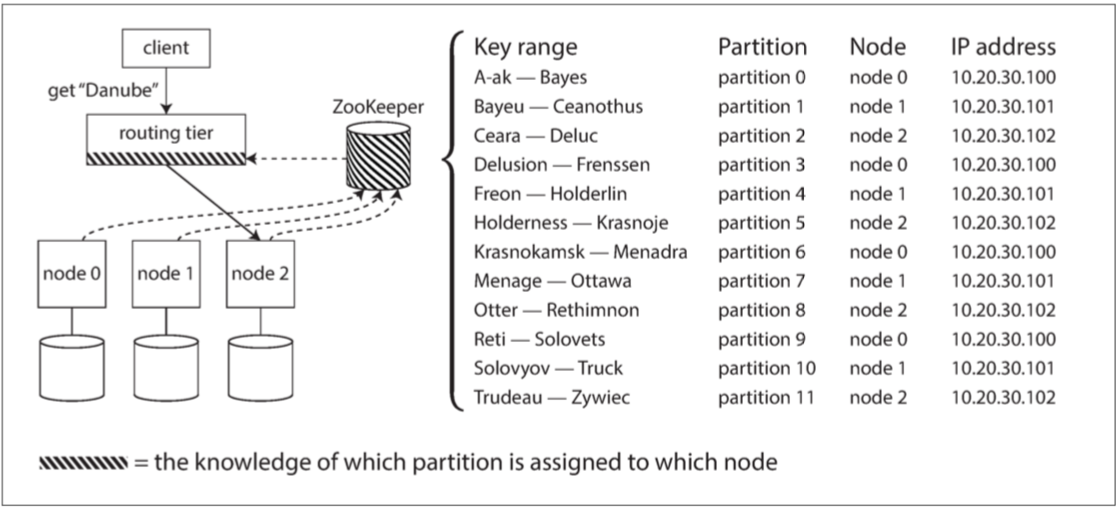
每個節點在Zookeeper中註冊自己 讓Zookeeper去維護partition -> node的map 任何人都可以向Zookeeper訂閱這個訊息 只要partition分配發生改變 還是新增或移除節點 Zookeeper就會通知路由層(可能是各個node 或是單獨一層 或是客戶端) 使得routing訊息保持在最新狀態
軟體業中的例子來說
LinkedIn的Espresso數據庫使用Helix
HBase,SolrCloud和Kafka使用Zookeeper
MongoDB依賴自己的config server
Cassandra和Riak採取不同的方法 他們在節點之間使用流言協議(gossip protocol)來散播集群的變化 這樣請求就可以發到任意節點(方法1) 該節點會轉發到包含所請求的partition的適當節點 這個模型在數據庫中增加了更多的複雜性 但避免了對於像是ZooKeeper這樣的外部協調服務的依賴
當使用方法1或方法2 向路由層或是隨機節點發送請求時 客戶端仍然需要找到要連接的IP地址 這些ip位置不像分區的節點變化那麼快 用個DNS就可以搞定
總結
本章討論了將大數據集劃分成多個小數據集的方式 數據量變大的時候 我們就無法只依賴單台機器 分區變得至關重要 主要目的是在多台機器上均勻分佈數據和查詢負載 避免出現熱點 並且需要在增加或移除節點的時候再平衡
主要的分區方法有兩種
1.key-range分區: key是有序的 每個分區擁有從某個最小值到某個最大值的所有鍵 排序的優勢在於可以範圍查詢 但如果應用程式常常訪問相鄰的key 可能會造成熱點 所以通常一個分區太大時 會把一個分區分成兩個小分區 動態的再平衡
2.Hash分區: 每個key都hash 每個分區有著固定範圍的hash值 這讓範圍搜尋變得不可行 通常先提前創建固定數量的分區 然後為每個節點分配多個分區 在新增節點時 把舊的多個分區移到新的節點
你要把這兩個方法混用也可以 比如說復合主鍵 使用key的第一部分來標識分區 而使用第二部分作為排序順序
別忘了次級索引也可以分區 有兩個方法
1.按文檔分區(本地索引) 其中二級索引存儲在與key和值相同的分區中 寫起來方便 讀的話 你必須對每個分區都發一樣的查詢
2.按關鍵詞分區(全局索引) 其中二級索引存在不同的分區的 讀起來方便 但寫的話你必須更新所有分區相關的次級索引
最後 我們討論了如何將查詢導到適當的分區
按照設計 多數情況下每個分區是獨立運行的 但是需要一次寫入多個分區的操作結果會很難預料(比如寫入一個分區成功 另一個失敗) 我們會在接下來的章節中詳加討論