Designing Data-Intensive Application - Batch Processing
November 24, 2019這是Designing Data-Intensive Application的第三部分第一章節: 批處理
本文所有圖片或代碼來自於原書內容
您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
批處理
本書的前兩部份 我們探討了很多關於request和query的問題以及相對應回傳的結果 許多現有數據系統中都採用這種方式: 你發送一個請求 一段時間後系統給出一個結果 不論系統是數據庫 緩存 搜索索引 還是Web Server都一樣
這樣子的online系統 因為請求通常是由人類發起的(瀏覽網站等等) 他們正在等待回覆 所以我們非常在乎系統的response time
因為Web和越來越多的基於HTTP/REST的API的系統 使得上述的這種請求/響應風格變得如此普遍 讓大家以為這是理所當然 但這並不是建構一個系統的唯一方式 我們總共有三種不同類型的系統
1.Service(online system)
Server等待客戶的請求或指令到達 對於收到的每一個請求 server都會盡快處理它 並回傳一個響應 回傳響應的時間通常是一個server性能的衡量指標 可用性非常重要
2.Batch processing system(offline system)
批處理系統有大量的輸入數據 需要跑一個job處理一些輸入 產生一些輸出 往往需要比較長的時間(幾分鐘到幾天都可能) 所以通常不會有用戶等待作業完成
批量作業通常會定期運行(比如一天一次) 而主要性能衡量標準通常是吞吐量 也就是處理特定大小的輸入所需的時間
3.Stream processing system(near-real-time system)
流處理介於online和offline之間 所以稱為near-real-time或是nearline
像批處理系統一樣 流處理消費輸入並產生輸出(並不響應需求) 但是 流式作業在事件發生後不久就會對事件進行操作 而批處理作業則需等待固定的一組輸入數據 這種差異使流處理系統比起批處理系統具有更低的延遲
在本章中我們將會看到 批處理是構建可靠 可擴展和可維護應用程序的重要組成部分 比如2004年轟動武林的Map-Reduce 被稱為是造就Google大規模可擴展性的算法 隨後也在各種開源數據系統中得到應用 包括Hadoop CouchDB和MongoDB
在本章中 我們將瞭解MapReduce和其他一些批處理算法和框架 並探索它們在現代數據系統中的作用
首先我們將看看使用標準Unix工具的數據處理 雖然可能你已經很了解了 但Unix的哲學也值得一讀 Unix的思想和經驗教訓可以遷移到大規模的分佈式數據系統中
使用Unix工具的批處理
來個例子 假設你有台Web服務器 每次處理請求時都會在日誌文件中附加一行 以下例子使用的是nginx預設的訪問日誌格式
216.58.210.78 - - [27/Feb/2015:17:55:11 +0000] "GET /css/typography.css HTTP/1.1" 200 3377 "http://martin.kleppmann.com/" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.115 Safari/537.36"事實上這只有一行 但因為排版問題看起來像是很多行 要讀懂一個日誌要先知道格式
$remote_addr - $remote_user [$time_local] "$request"
$status $body_bytes_sent "$http_referer" "$http_user_agent"
所以這一行日誌的意思是
在2015年2月27日17:55:11 UTC的時候 服務器收到從ip位址216.58.210.78的地方 接收到對文件/css/typography.css的請求 但因為用戶沒有被認證 所以$remote_user被設置為- response code 200代表響應成功 response的大小是3377bytes 網頁瀏覽器是Chrome 40 http://martin.kleppmann.com/ 頁面中的引用導致該文件被加載
分析簡單日誌
很多工具可以從這些日誌文件生成關於網站流量的漂亮的報告 但我們來自己練習一下Unix的基本工具 假設你想要在你的網站上找出五個最受歡迎的網頁
cat /var/log/nginx/access.log | #1
awk '{print $7}' | #2
sort | #3
uniq -c | #4
sort -r -n | #5
head -n 5 #6這一行命令做了什麼呢
1.讀取日誌文件
2.每行只輸出第七個字段(請求的URL) 在上例是/css/typography.css
3.按字母順序排列請求的URL表 如果一個URL出現過n次 那排序後這個URL會連續出現n次
4.uniq 命令通過檢查兩個相鄰的行是否相同來過濾掉輸入中的重複行 -c 表示還要輸出一個計數器 表示出現過幾次
5.按每行起始處的數字排序(-n) 這是URL的請求次數 大的數字在前(-r)
6.只輸出前五行(-n 5)
輸出如下所示
4189 /favicon.ico
3631 /2013/05/24/improving-security-of-ssh-private-keys.html
2124 /2012/12/05/schema-evolution-in-avro-protocol-buffers-thrift.html
1369 /
915 /css/typography.cssUnix工具非常強大 他可以在幾秒內處理幾GB的日誌文件 還可以根據需要輕鬆修改命令 只要你能輕鬆自在的運用awk sed grep sort uniq和xargs 那你幾乎可以做出決大部分的資料分析
自定義程序
除了Unix的chain of command之外 你還可以寫一個簡單的程序來做同樣的事情
counts = Hash.new(0) # 1
File.open('/var/log/nginx/access.log') do |file|
file.each do |line|
url = line.split[6] # 2
counts[url] += 1 # 3
end
end
top5 = counts.map{|url, count| [count, url] }.sort.reverse[0...5] # 4
top5.each{|count, url| puts "#{count} #{url}" } # 51.counts 是一個計數器的HashMap 保存了每個URL被瀏覽的次數 初始值為0
2.逐行讀取日誌 每行第七個被空格分隔的字段為URL
3.把HashMap中相對應的值加一
4.按計數器值對哈希表內容進行排序 並取前五位
5.印出前五個URL
這段程式不像Unix command那麼簡潔 但卻好懂很多 執行的流程也有很大的差異
sorting VS in-memory aggregation
Ruby腳本在內存中保存了一個URL的HashMap 但Unix沒有 Unix依賴的是先對所有URL排序 排序完之後再把重複出現的加起來
哪種方法好呢 如果你只是個刷題機器 你可以輕鬆地回答 這也太簡單了吧 Ruby時間複雜度O(n) Unix時間複雜度O(nlogn) 哪有什麼好比?

但正確答案是取決於你的應用 如果造訪你網站的都是那一兩個網站 來了一兩百萬次 那對Ruby來說 就只是一個HashMap的Entry 那即使在一個性能很差的筆電也跑得起來
但如果造訪你的網站的網站有上千萬個每個都只來一兩次 那可能每個網站的網址加起來放不進你的內存 整個程式Crash 這種時候 Unix sort就可以派上用場了 為什麼呢 因為排序的優點就是可以高效地使用磁盤 我們在SSTables和LSM樹中討論過的原理是一樣的 數據可以一次提出一些進內存 排序完再丟回硬碟 每一段排序好的再merge成一個大的排序文件
Linux的sort就利用這種方式來應對大小超過內存的數據 並且還能同時使用多個CPU平行排序 這代表我們的Unix sort方法更容易可以擴展到大數據集 而且還不會耗盡內存 當然瓶頸可能是從硬碟讀取文件的速度
Unix哲學
Unix pipes的發明人 Doug McIlroy 在1964就提出了他的看法
當我們需要將消息從一個程序傳遞到另一個程序時 我們需要用類似水管拼接的方式 I/O也是一樣
這個Unix哲學在1978年被表述如下
1.讓每個程序都做好一件事 如果你要做新的工作 就寫一個新的程序 而不是透過添加功能來讓舊程序複雜化
2.期待每個程序的輸出成為另一個程序的輸入 不要輸出無關的信息 不要用互動式的輸入
3.設計和構建軟件要儘早儘快嘗試 最好在幾週內完成 看到笨拙的部分不要猶豫 重建重寫
4.優先使用工具來減輕編程任務 即使你編程完之後工具就沒用了也是一樣
這些想法(自動化 快速迭代 將大項目分成可管理的小項目)聽起來非常像今天的敏捷開發和DevOps運動 意外的是 變化其實不大
sort指令就是一個很好的例子 即使我們知道他比大部分的語言標準庫的實現還要好 但單獨使用sort幾乎沒有什麼效用 它只能與其他Unix工具(如uniq)結合使用
像bash這樣的Unix shell可以讓我們輕鬆地將這些小程序組合成強大的數據處理任務 儘管這些程序中 不同的指令是由不同人編寫的 但它們可以靈活地結合在一起 Unix是如何實現這種可組合性呢?
統一的接口
如果你希望一個程序的輸出成為另一個程序的輸入 那意味著這些程序必須使用相同的數據格式 簡稱 兼容接口(compatible interface)
在Unix中 這個接口就是文件(file)(或是準確的說 一個file descriptor) 一個文件就是一個sequence of bytes 因為這個接口簡單易懂 所以各種應用可以輕易地連接在一起 比如文件系統的真實文件 或是process跟process之間的communication channel 或是 device driver(/dev/audio, /dev/lp0) 或是TCP的socket
雖然不夠完美 但幾十年來 統一的Unix接口仍然是非常出色的設計 沒有太多軟件可以像Unix工具之間整合的這麼好
logic與wiring相分離
Unix工具的另一個特點是使用標準輸入stdin和標準輸出stdout 如果你運行一個程序 而不指定任何其他的東西 標準輸入來自鍵盤 標準輸出指向螢幕 但你可以輕易把輸入(輸出)改成文件 或者是把某個程序的stdout導到另一個程序的stdin
程序本身並不需要處理輸入輸出 使得程式開發變得簡單很多(想想我們寫python要爬一個文件 需要去研究一些file IO的東西 而且如果輸入改成非文件 我們還要改程式去讀輸入)
透明度和實驗
Unix工具的成功還有其他原因
1.Unix命令的輸入文件通常被視為不可變的 這表示你可以隨意運行命令 跑跑看結果如何
2.查看結果的時候 還可以用less 看是不是符合預期格式
3.可以將一個流水線階段的輸出 寫入文件 並用該文件作為下一階段的輸入 這讓你可以重新啟動後面的階段 而無需重新運行整個管道
所以你如果只是想實驗看看某些結果 Unix非常好用
侷限
Unix最大的侷限 就是只能在同一台機器上運行 這時候就要帶入今天的主角 - MapReduce
MapReduce和分佈式文件系統
MapReduce有點像Unix工具 只是分佈在數千台機器之上
和Unix工具一樣 運行MapReduce作業通常不會修改輸入 除了生成輸出外沒有任何副作用
相對於Unix工具使用stdin和stdout作為輸入和輸出 MapReduce作業在分佈式文件系統上讀寫文件 在Hadoop的Map-Reduce實現中 該文件系統被稱為HDFS(Hadoop分佈式文件系統) - 一個Google文件系統(GFS)的開源實現
HDFS是由每台機器上的守護進程(daemon process)所組成 這個進程對外expose網路的服務讓大家存取機器裡面的文件 名為NameNode的中央服務器會跟蹤哪個文件塊存儲在哪台機器上 因此HDFS在概念上創建了一個大型文件系統 可以使用所有有跑守護進程的機器的Disk
當然為了容錯 文件塊被複製到多台機器上 複製意味著多個機器上的相同數據的多個副本 跟RAID類似
MapReduce作業執行
MapReduce是一個programming framework 你可以寫代碼來處理HDFS等分佈式文件系統中的大型數據集 理解他的最簡單方式 就是參考分析簡單日誌中的Web服務器日誌分析例子 MapReduce處理方法類似
1.讀取一組輸入文件 並將其分解成記錄(records) 在Web服務器日誌示例中 每個record都是一行
2.調用Mapper函數 從每條輸入記錄中提取一對key-value 在Web服務器日誌示例中 Mapper函數就是 awk '{print $7}' 他拿了URL($7)作為key, value是空
3.對所有的(key, value) 按照key排序 在Web服務器日誌示例中 我們用sort
4.調用Reducer函數 遍歷排序後的key-value pair 如果同一個key出現過很多次 因為sort的關係 他們會出現在一起 在前面的例子中 Reducer是由uniq -c命令實現的 該命令使用相同的鍵來統計相鄰記錄的數量
這四個步驟 就是一個MapReduce的作業執行 步驟2(Mapper)和步驟4(Reducer)是你編寫代碼的地方 步驟1由輸入格式解析器處理 步驟3會自動被處理
所以要創建一個MapReduce作業 你需要實現兩個 函數 Mapper和Reducer
Mapper: Mapper會在每條輸入記錄上調用一次 其工作是從輸入記錄中提取key-value 對於每個輸入 他可以生成任意數量的key-value pair 他不會保留一個紀錄到下一個記錄的任何狀態 因此每個記錄都是獨立處理的
Reducer: 得到由Mapper生成的key-value pair 收集屬於同一個key的所有值 並在所有的value上面調用reducer Reducer可以產生輸出記錄(比如相同URL出現的次數)
我們在Web服務器日誌示例中的第五步有第二個sort 這代表的是對於URL的數目排序 在這裡要達到這件事 必須在寫一個獨立的Mapper/Reducer來做到
分佈式執行MapReduce
講完MapReduce的概念後 來看看為什麼MapReduce比Unix強 強就強在MapReduce可以分佈式的在很多機器上運算 不需要編寫代碼來處理並行的問題 Mapper和Reducer一次處理一條記錄 它們不需要知道它們的輸入來自哪裡 或者輸出去往什麼地方 MapReduce框架已經幫他們處理好在機器之間移動數據的複雜問題
下圖顯示了Hadoop MapReduce作業中的數據流
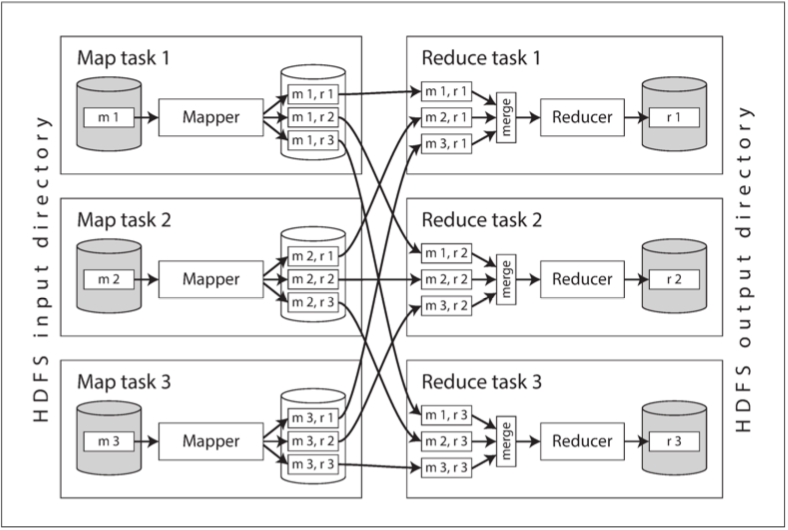
相較於一般的程序 我們寫完代碼後 把資料從磁碟拉到內存來跑 在MapReduce裡面 我們是把程序送到有資料的機器 因為程式碼相較於要處理的數據而言太小 所以我們寧願傳輸程式碼 節省網路開銷
把Mapper傳輸到每個機器之後呢 開始跑 針對每一條紀錄 一條一條執行程式 Mapper的輸出是許許多多的key-value pair
雖然Mapper的數量由輸入文件塊的數量決定 但Reducer的任務的數量是由作業者配置的(可以跟mapper的數量不一樣) 為了保證每個Reducer拿到相同的key 我們使用一個hash來針對key分配每個key-value pair要去哪個Reducer
但別忘了在丟給Reducer之前我們要先排序 那要是所有的key-value pairs太多存不進內存怎麼辦 我們在SSTables和LSM樹討論過這個問題
Reduce任務從Mapper獲取文件的同時文件已經有個有序性 因此 如果不同的Mapper生成了鍵相同的記錄 則在Reducer的輸入中這些記錄將會相鄰
在呼叫Reducer時 我們會給入key和iterator 那Reducer就可以使用這個iterator來跑遍所有的key-value pair 來產生任意數量的輸出記錄 這些輸出記錄會寫入分佈式文件系統上的文件中(通常是先寫在Reducer本身的機器中 然後再複製給其他機器留副本)
MapReduce工作流
單個MapReduce作業可以解決的問題範圍很有限 我們剛剛討論的Map-Reduce就只能統計每個URL出現的次數 如果你要對次數排序 你需要另外一個Map-Reduce作業
所以我們把Map-Reduce作業們接成工作流(workflow) 比如說一個作業就是下個作業的輸入 對於MapReduce框架來說 這兩個是獨立的作業 只是我們在寫的時候就要先安排好 第二個作業的輸入HDFS目錄需要是第一個作業的輸出HDFS目錄
只有當作業成功完成後 批處理作業的輸出才會被視為有效的(MapReduce會丟棄失敗作業的部分輸出) 所以下一個作業需要等到前一個作業全部成功完全 才會開始進行 各大公司有很多的workflow scheduler被廣泛應用 比如說Oozie, Azkaban, Luigi, Airflow, Pinball等等
Hadoop的各種高級工具(如Pig Hive Cascading Crunch和FlumeJava) 也能自動布線組裝多個MapReduce階段 生成合適的工作流
Reduce-Side Join
在數據庫中 如果執行只涉及少量記錄的查詢 數據庫通常會使用索引來快速定位感興趣的記錄 如果查詢涉及到Join 那就可能涉及到查找多個索引 可是MapReduce沒有索引的概念
當MapReduce作業被賦予一組文件作為輸入時 它讀取所有這些文件的全部內容 數據庫會將這種操作稱為全表掃瞄 當然如果你只是想搜尋少量的紀錄 這樣的操作非常耗時 可是在分析查詢中 通常需要大量數據的Aggregate 所以可以接受 更何況我們是在多台機器中執行查詢 所以全表掃描也是很合理的事情
我們來試著分析一個用戶活動事件
左邊是事件日誌 描述用戶在網站上做的事 右側是用戶數據庫
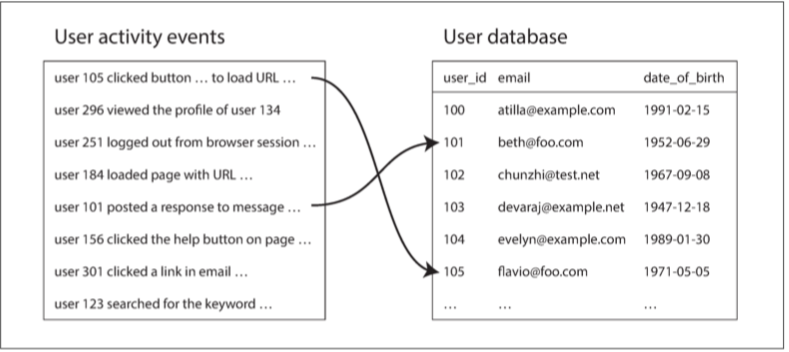
當我們想要分析網站 (比如說哪些頁面比較受年輕人歡迎) 我們理所當然的需要把兩個表按照userId先join起來
Join這件事要怎麼做到呢 我們要有個mapper跑在用戶活動上 key是userId, value是查看的頁面
另一個mapper跑在使用者資料上 key是userId, value是生日
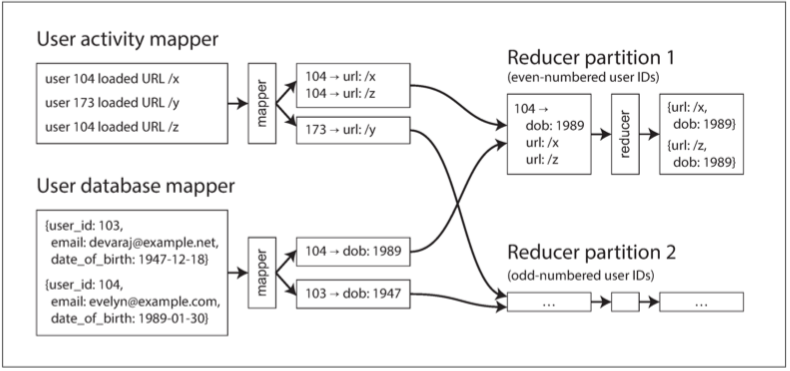
MapReduce框架通過key對Mapper輸出進行分區 同一個key會導給同一個Reducer 那既然在同一台機器上 那join起來就是輕鬆愉快
處理傾斜skew
問題來了 如果某個key的key-value特別多呢 這使得每個Reducer處理的量不一樣 (這其實是很常見的事 比如某些名人的發文就是比較多人關注) 這樣那個處理這個hot key的Reducer會處理比別人多很多事 而Map-Reduce作業的結束是決定於所有Reducer結束 這樣就會讓很多Reducer資源閒置在那邊等
解法當然就是讓多個Reducer一起處理囉 Pig的skew join就是在一開始先取樣一下 找找看哪些key是hot-key 把這些hot-key給多幾台的Reducer處理 當然另外一邊(使用者資料的Map-Reduce)的Mapper的輸出結果要給進這些Reducer裡 每個Reducer做完之後呢 再用一個額外的Map-Reduce工作 把所有處理hot-key的Reducer的結果合併起來
Mapper-side Join
上一節的算法 主要是在Reducer端處理實際上的join邏輯 Mapper只是扮演著預處理輸入數據的角色
Reduce端方法的優點是不需要對輸入數據做任何假設 因為給到我手上的一定有著同樣的key 但缺點就是排序 複製到reducer 或是從多個reducer中合併的操作可能開銷巨大
如果你能夠對輸入數據做一些假設 則通過使用所謂的Map端連接來加快連接速度是可行的
這樣的話 我們就只需要Mapper 不用sorting 不用Reducer
broadcast hash join
如果是一個大數據跟一個小數據join 而小數據小到可以放進內存 以這個例子來說 如果User資料庫可以整個放進Mapper的內存空間 那簡直輕鬆愉快 每個Mapper程序掃瞄自己被分配到的用戶活動事件後 把每個userId都跟內存的用戶資料join一下就搞定
為什麼叫做廣播散列連接(broadcast hash join) 因為這有點像是把小資料庫廣播給所有Mapper
Partitioned hash join
如果兩個輸入(用戶活動 用戶資料)有著相同數量的分區 而且以相同的hash function來按照userId分區 那我們就可以加速
比如說用戶活動資料庫跟用戶資料戶總共被partition成10個 按照userId%10來分 那我們就可以用10個Mapper 每個Mapper去讀相對應的partition的資料 各自join搞定
批處理工作流的輸出
我們已經說了很多用於實現MapReduce工作流的算法 但還沒討論這些輸出可以用來幹嘛
建立搜索索引
先來看看MapReduce 最大的受益者 Google 他們就是因為搜尋引擎一飛沖天 基本上 Mapper把所有文檔分區 Reducer把不同partition的文檔建立index 這種分工方式非常適合並行處理
那如果少量文檔的內容發生更改 其中一個選擇是定期把所有的文檔重新跑一遍 跑完就用新的索引文檔全部取代舊的 缺點是計算成本高 優點是好理解 文檔進文檔出
另一個選項就是增量建立索引(incremental index)
批處理輸出key-value store
搜索索引只是批處理工作流可能輸出的一個例子 批處理的另一個常見用途是構建機器學習系統 這類批處理作業的輸出通常是某個數據庫 讓網路服務器可以給定UserId回傳他有興趣的商品 或是可能的好友之類的應用
可是Hadoop輸出的地方是HDFS 網頁服務器是跟數據庫溝通 批處理過程的輸出如何回到Web應用可以查詢的數據庫中呢?
最直接的方式 就是直接在Mapper或Reducer中使用你數據庫的Client 從處理作業直接寫入數據庫服務器 一次寫入一條紀錄 這方法可行 但不是個好主意 因為
1.為每條記錄發起一個網路請求 跟批處理本身的工作速度比較起來 完全不是同一個數量級 而且即使數據庫client支持batch process 性能也鐵定好不到哪去
2.如果每個Reducer同時寫入相同的輸出數據庫 並以批處理的預期速率工作 那麼該數據庫很可能被輕易壓垮 無法提供其他正常的就查詢功能
3.MapReduce為作業的輸出提供了全有或全無的保證 如果作業成功 那就是每個紀錄都被執行一次 如果失敗就是全部沒有 但對於一個外部的系統(數據庫) 我們幾乎無法保證有同樣的全有或全無效果 在創建數據庫紀錄的過程無法隔離其他使用者 所以其他使用者還是可以存取到半成品
所以好一點的解決方法 是在批處理作業內創建一個全新的數據庫 並將其作為文件寫入分佈式文件系統中作業的輸出目錄 這些數據文件一旦寫入就是不可變的 可以批量加載到處理只讀查詢的服務器中 不少的key-value store都支持在MapReduce作業中構建數據庫文件 包括Voldemort, Terrapin, ElephantDB, HBase等等
將數據加載到Voldemort時 服務器將繼續用舊數據文件服務請求 同時將新數據文件從分佈式文件系統複製到服務器的本地磁盤 一旦複製完成 服務器會自動將查詢切換到新文件 如果在這個過程中出現任何問題 它可以輕易rollback至舊文件 因為它們仍然存在而且不可變
批處理輸出的哲學
本章前面討論過的Unix哲學 鼓勵以指明數據流的方式進行實驗 讀取輸入 寫到輸出 你可以重複執行不同的指令來做任何你想要的改動或調試 不會改變到輸入 也不會有副作用
MapReduce作業的輸出處理遵循同樣的原理 在將輸入視為不可變且避免副作用的前提下 批處理作業不僅實現了良好的性能 而且更容易維護
1.如果你的Mapper或Reducer有bug 你可以改完後直接重跑 輸出就會被糾正了 相對於具有讀寫事務的數據庫則沒有這個屬性 如果你部署了錯誤的代碼 將錯誤的數據寫入數據庫 那麼即使回滾代碼也無法修複數據庫中的數據
2.由於回滾很容易 比起在錯誤意味著不可挽回的傷害的環境 功能開發進展能快很多 在敏捷開發的環境中(Agile) 叫做最小化不可逆性(minimizing irreversibility)
3.如果Map或Reduce任務失敗 MapReduce框架將自動重新調度 並在同樣的輸入上再次運行它 如果失敗是因為代碼有問題 那就會持續失敗 但如果故障是臨時的機器問題 那麼故障就會被容忍 因為輸入不可變 所以多次重試都是安全的
4.與Unix工具類似 MapReduce作業將logic與wiring分離
高級API和語言
雖然MapReduce在二十世紀後期變得非常流行 並受到大量的炒作 但它只是分佈式系統的許多可能的編程模型之一 我們在這一章花了很多時間來討論MapReduce 因為他是分佈式文件系統的一種相當簡單明晰的抽象 這裡的簡單指的是理解起來很簡單 而不是寫起來很簡單 事實上 對於每件事都要寫map/reduce是很累人的
所以 有很多高級一點的編程模型就被實現了 Pig, Hive, Cascading, Crunch這些建立在Map/Reduce之上的抽象 學起來都非常簡單 Spark和Flink也有它們自己的高級數據流API 通常是從FlumeJava中獲取的靈感
總結
在本章中 我們討論了批處理 我們先討論了Unix的工具(awk, grep, sort等等) 然後我們看到了如何把這些工具的理念應用到MapReduce 某些設計原則非常類似: 輸入是不可變 輸出是另一個程序的輸入
在Unix世界中 讓程序跟程序之間組合起來的接口是file跟pipe 在MapReduce的世界中 則是分佈式文件系統
分佈式批處理框架常需要克服的兩個主要問題是:
1.分區: Mapper根據輸入文件塊進行分區 Mapper的輸出被重新分區 排序 然後合併給Reducer 目的是把一系列的相關數據都放到同一個地方
後MapReduce時代的數據流引擎若非必要會儘量避免排序 但它們也採取了大致類似的分區方法
2.容錯: MapReduce經常需要寫入Disk 所以如果有單獨一個小任務失敗的話 不用重啟整個作業 就是重跑那個小小的任務就可以 但當然因為要寫進Disk 所以速度也慢很多
我們還討論了幾種MapReduce的Join算法
1.Sort-merge joins: 每個輸入紀錄 都通過一個Mapper產生一個可以被join的紀錄 通過分區 排序 合併到同一個Reducer之後 就可以輸出一個join完的結果
2.Broadcast hash join: 兩個Join輸入的其中之一很小 可以塞進內存的話 就把這個小的塞到每個Mapper的內存 就輕鬆搞定Join
3.partitioned hash join: 如果兩個Join的輸入以相同的方式分區 則可以獨立地對每個分區Join
分佈式批處理引擎有一個刻意限制的編程模型: Callback function(map/reduce) 被假定是stateless的 除了輸出之外 沒有任何顯著的副作用 這一個抽象讓MapReduce的框架隱藏了很多分布式系統中的困難問題 比如說遇到崩潰跟困難時 framework可以安全的一直重試 任何失敗任務的輸出都被丟棄
因為抽象的很漂亮 所以你在用的時候 根本不用擔心底層的容錯機制 framework保證了如果有輸出的話 這個輸出就跟沒有發生錯誤的情況長得一樣 所以這種批處理的可靠性比起在線的online service都強很多
批處理的特點是 輸入數據是有界的(bounded) 他有一個已知的 固定的大小 所以一個任務可以明確的知道他是否已經完成
下一章中 我們會討論流處理 流處理的輸入是無界的(unbounded) 在這種情況之下會有許多更好玩複雜的問題值得探討