Designing Data-Intensive Application - Replication
February 12, 2019這是Designing Data-Intensive Application的第二部分第一章節: 複製
本文所有圖片或代碼來自於原書內容
您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
複製
開宗明義 複製就是在不同台機器都保留相同數據 原因有以下幾點
1.使數據的位置和用戶地理上接近些(減少延遲)
2.即使部分系統發生故障 總系統還是可以運作(可用性)
3.讓多台機器可以服務讀請求(增加讀吞吐量)
本章討論的內容 主要假設是你的總數據很小(都可以存在一台機器內) 下一章才會放寬這個假設 變成總數據很大(無法放在一個數據內 必須分區存)
如果複製的東西不會變 那就是只要複製一次 打完收工 複製的難點就是就是處理數據的變化 我們會討論三種流行的處理複製數據變化的算法 單領導者(single leader) 多領導者(multi leader)和無領導者(leaderless)
除了不同算法之外 本章還會討論一些重要的trade-off 比如說要同步複製還是異步複製? 失敗的副本怎麼處理?等等許多不同的配置選項 還會討論這些決策的後果
30年前 基本所有資料都是一台機器搞定 分布式的概念也是最近才開始紅 很多重要的名詞很多人都不是完全清楚比如最終一致性(eventual consistency) 或是 自讀自寫(read-your-writes) 或是單調讀(monotonic read) 讀完這章你就會都明白了
Let’s go!
領導者與追隨者
存儲數據庫備份的節點 稱為副本(replica) 當存在很多個副本節點的時候 就必須要處理一個問題 如何確保所有數據都在所有的副本裡?
每一次向數據庫的寫入 都要傳播到所有副本上 否則副本就會有不一樣的數據 最常見的解法是 基於領導者的複製(leader-based replication) 也稱 主被動複製(active/passive) 也稱主從複製(master/slave)
工作原理如下:
1.副本之一被指定為領導者(leader, master, primary) 當有客戶要寫數據 就寫到領導者
2.其他副本被稱為追隨者(follower, read-replica, slave, sencondaries, hot-standby) 每當領導者寫入領導者本地的數據庫時 也會將數據變更發給所有追隨者 稱為複製日誌(replication log)或變更流(change stream) 每個追隨者就可以從這些日誌更新自己的數據庫 當然 是按照同樣的修改順序
您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
3.當客戶想要讀取數據 他可以向領導者或追隨者讀都可以
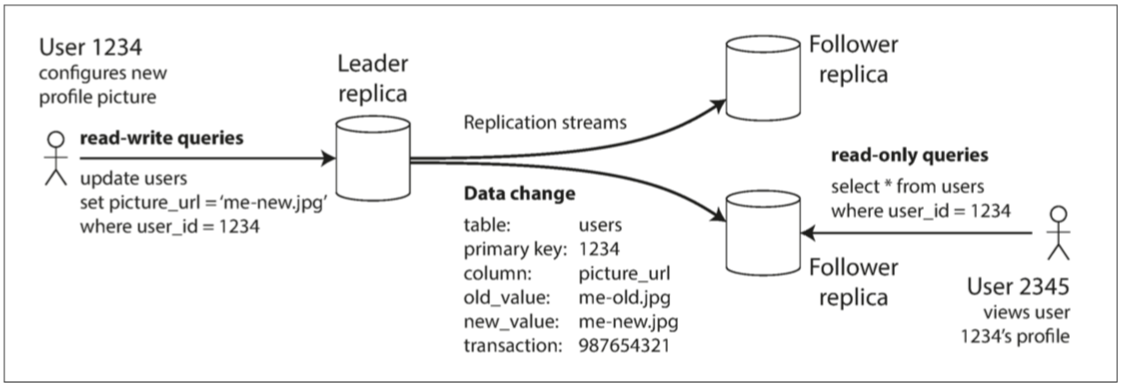
這種master-slave的複製已經是許多主流數據庫的內建功能 比如PostgreSQL, MySQL, Oracle, Data Guard 即使是非關聯性數據庫也在用 像MongoDB RethinkDB Espresso
這種複製不是只用於數據庫 講求高可用的Message Queue(Kafka或RabbitMQ) 也是用同樣方式達到high availability的需求
同步複製還是異步複製
複製系統的一個重要細節是 複製是同步發生還是異步發生 看回剛剛的圖 一個使用者更換了大頭照 客戶對主數據庫發請求 然後主數據庫將數據變更轉給從庫
這時候主庫有兩個選擇 第一個 是等從庫寫好回傳給我後 我再回應客戶(同步) 第二個就是不等 直接回應客戶(異步)
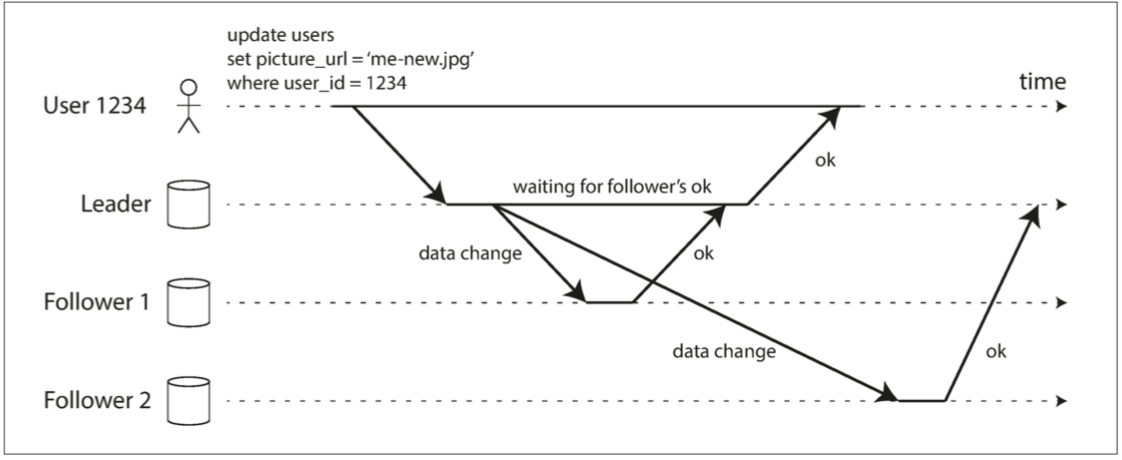
上圖中 Follower1就是同步 Follower2就是異步
同步複製的優點: 就是保證主庫跟從庫都同時擁有最新的版本 如果主庫突然失效 這些數據仍然能在從庫上上找到
同步複製的缺點: 就是寫入從庫可能會很久(比如從庫正在從故障中自我修復 或是從庫節點出現網路問題 或是 系統正在最大capacity下運行) 更慘的是如果從庫寫入失敗 主庫還必須reverse自己的寫入來達到一致 所以要回傳客戶寫入失敗
所以 將所有從庫都設置為同步的是不切實際的 任何一個節點的中斷都會導致整個系統停擺(因為只要一個節點無法寫 所有人都不能寫) 所以有一個解法 就是只有最少一個從庫是同步的 其他都是異步的即可 當你發現你要同步的那個從庫有點慢或沒回應 就把它跟一個原本異步的交換就可以
這樣我又不會寫太久 又不會讓一個單獨從庫阻擋了寫操作 又保證同一時間一定最少兩個數據庫有最新最正確版本 這配置稱為半同步(semi-synchronous)
當然你也可以設置成完全異步 優點就是即使所有從庫都爆了 你還是可以繼續寫 缺點就是主庫變成single point of failure 如果主庫爆了 所有還沒寫入從庫的更新都不見了 所以即使客戶已經收到了更新成功的訊息 你的資料還是可能不持久(Durable)
雖然為了異步複製犧牲了持久性聽起來不太好 但現實生活中這是很廣泛使用的方式 我們會在複製延遲問題中再討論這個問題
設置新從庫
有時候我們想要多加一個從庫 可能是為了增加副本的數量 也可能是為了替換一個壞掉的從庫
在你複製的同時 主庫仍然有新的寫正在進行 我們該如何保證新的從庫擁有主庫的正確版本呢
解法一 也是最差的解法 就是block寫請求 簡單但違反了availability的需求
解法二 先把主庫照一個snapshot 把snapshot的內容複製到從庫 複製完之後 再跟主庫拿照了snapshot之後的所有log
您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
處理節點停機
系統中的任一節點都可能會停機 可能是計劃中的維護 可能是意外的故障 無論是什麼理由 我們的大目標就是不影響整體的運作
從庫停機: Catch-up recovery
如果是從庫當機 就比較簡單 因為你可以找得到你從庫處理的最後一個transaction 然後你再去跟主庫要你錯過的transaction就可以了
主庫當機: Failover
主庫失效就棘手一點 你必須把一個從庫拉成主庫 還得重新配置客戶端 讓他們知道現在的主庫換人了 其他從庫也必須知道主庫換人 這樣他們有需要可以向新主庫拉變更
這個過程稱為故障切換(Failover) 可以手動進行 也可以自動進行 如果是自動進行的話 步驟如下
1.確認主庫失效: 主庫失效原因可能很多 停電 崩潰 網路問題等等 沒有太好的方法可以知道為什麼失效 我們只能用簡單超時(timeout)判斷 也就是節點跟節點之間頻繁地傳消息 如果一個節點在一段時間內(30s之類)沒有回應 就認為他掛了
2.選擇一個新的主庫: 可以藉由選舉過程(所有副本投票) 也可以由之前指定的控制器節點(controller node) 直接指定 通常最佳人選是擁有最新的主庫更新的從庫 讓所有節點同意一個新領導者是一個共識問題 第九章會再討論
3.重新配置系統來啟用新主庫: 客戶將寫請求發給新主庫 如果舊主庫修復了 舊主庫會以為自己還是主庫 系統也必須確保老主庫要認可舊主庫 變成一個從庫
您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
故障切換有許多大麻煩如下:
1.在異步複製的系統中 如果新主庫沒有收到老主庫停機前最後的寫入 在選出新主庫後老主庫連回來了 這個情況下在老主庫的那些寫入就只有他自己有 造成了conflict
解法也簡單 就是丟棄那些conflict寫入 但這就可能打破客戶對於durable的期望
2.如果數據庫有跟其他外部的存儲一起合作的話 那第一點的丟棄寫入內容就很危險 講一個Github的例子 某次一個沒有擁有所有主庫更新的從庫被拉成新主庫 而資料庫使用auto-incrementing counter當作primary key 因為新的主庫當初有一點累格 所以他並不知道某些id已經被舊主庫用掉了 新主庫重用了那些id 這些id同時被外部的Redis所用 這使得Redis裡面的數據不一致 最後導致一些私有數據洩漏到錯誤的用戶手中
3.在發生某些故障時(第八章會再說明) 可能會出現兩個節點都以為自己是主庫的情況 稱為split brain 非常危險 如果兩個主庫都可以接收寫需求 卻沒有衝突解決機制(見多領導者複製) 那麼數據就可能丟失或損壞 好一點的系統會自動關閉一個主庫 差一點的就是兩個都會被關閉
4.判定主庫超時的時間應該要是多久? 超時時間設定太長 可能會讓系統等很久才發現異樣 太短也可能發生不必要的故障切換
這些其實對於自動故障切換都挺麻煩的 沒有簡單的解法 所以大多數運維團隊還是願意手動執行故障切換
節點故障 不可靠的網絡 副本一致性的trade-off 持久性 可用性等等的議題都是分布式系統中的基本問題 我們會在第八第九章深入討論
複製日誌的實現
我們剛剛提到了不少次日誌的實用性 可能是設置新從庫或是處理節點停機 那到底數據庫底層是怎麼實現的呢
基於語句的複製Statement-based replication
最簡單的 主庫紀錄了它執行的每個請求statement 並將該stetement日誌發送給從庫
對關聯數據庫來說就是INSERT DELETE UPDATE等等 每個從庫收到時就好像從客戶手中收到一樣
聽起來很好啊 有什麼問題咧?
1.任何使用了非確定性函數(nondeterministic)的statement 都會造成數據不一致 比如使用NOW()得到當前時間 或是使用RAND()得到一個隨機數
2.如果語句是auto-increment 或是語句依賴數據庫的現有數據 那你就必須保證每一個transcation必須要按照相同的順序執行 當你想支持併發transaction的時候 這就會變成限制
3.有副作用的語句 可能會在不同的副本產生不同的副作用
問題實在有點多 大多數不採用這個最直觀的日誌實現
WAL (Write-ahead log)
我們之前討論過預寫式日誌(WAL write-ahead-log) 也是儲存引擎在Disk上保存數據的方式 來複習一下
1.關於日誌結構儲存引擎 log是主要的存儲方式 而且log segment可以在後台壓縮並進行垃圾回收
2.對於覆寫單個磁盤塊的B樹 每次修改前都會先寫入WAL 以便崩潰後可以修復
我們也可以效仿這個append-only的結構 來把主庫的log丟給從庫 來達到複製的目的 只要從庫跟著主庫所有的日誌一步一步執行 就會長得跟主庫一樣
聽起來簡單容易 但缺點是log的數據非常底層 詳細到哪個硬碟的哪個byte被改了 這使得複製和底層存儲實作被緊密結合 如果今天數據庫需要更改存儲格式(從一個版本更改為另一個版本) 那幾乎不可能在不同版本間操作 一定要全部一起變動
上述缺點看似微小 但卻對於運維產生巨大的影響 好一點的情況 是複製協議允許從庫使用比主庫更新的版本 那我們還可以先升級從庫 再使用故障切換把已經升級的從庫拉成主庫 壞一點的情況(就是複製協議不允許版本不匹配) 那就一定需要停機 所有主庫從庫版本升級後才能繼續運作 失去availablility
邏輯日誌複製(Row-based)
另一個方法 就是複製和存儲引擎使用不同的日誌格式 這樣可以讓複製跟存儲de-couple
比如說複製端的日誌只需要明確的寫明足夠資訊
1.對於新插入的row 日誌中當然每個column的資訊都要有
2.對於刪除的row 日誌中只要有primary key就可以
3.對於更新的row 日誌中需要有primary key和row中被修改的column的新值
存儲接受到後 就照自己底層的存儲方式紀錄 你可以想成一個之前是強迫所有人講英文 這個解法是複製可以講西文 存儲可以講中文
這個解法的好處就是領導者和跟隨者能夠運行不同版本的數據庫軟件或是不同的底部存儲
如果你的數據庫還需要跟外部的應用程式合作 邏輯日誌複製也更容易合作 比如說需要跟數據倉庫合作分析 或建立索引或緩存等等 也稱為獲取數據變更(change data capture) 第11章會再提到
Trigger-based的複製
目前為止的複製方法都是數據庫實現的 應用程式基本上毫不知情
但某些特殊情況我們需要更多的靈活性 比如說我們只想複製數據的一部分 或者想處理寫入衝突 等等 那就可以把複製的邏輯移到應用程式層
有些工具 比如說Oracle Golden Gate 可以通過讀取數據庫日誌 來讓你的應用程式使用數據 另一種方式是使用數據庫自帶的功能 trigger或stored procedures
Trigger可以讓你在數據庫發生特定事件時 寫入另一個table 再由另一個process去讀取這個table 再去跑你想要的業務邏輯(比如複製數據到其他副本等等)
這個方式會比其他複製方法具有更高的開銷 而且比數據庫內建的方式容易出錯 限制也很多 但靈活性比較強
您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
複製延遲問題
我們之前提到 容忍節點故障只是需要複製的一個原因 其他複製的原因還有可擴展性(處理比單個機器更多的請求) 跟延遲(讓副本在地理位置上更接近用戶)
剛剛提到的寫入到主庫 從從庫讀取 可以應付大多應用程式的邏輯(讀多寫少) 所以你的從庫越多 你就可以支持越多的讀
說來容易 但以上只出現在異步複製 如果你想要同步複製到很多的副本 那只要任何一個掛了或是任何一個副本很慢 那你的系統整的都慢 但你要異步的話 有可能會有從庫落後的情況 因為可能你從主庫讀跟從從庫讀會讀到不同的結果 這種不一致性只是暫時的 從庫最終會趕上主庫並保持一致 稱為最終一致性(eventually consistency)
這個複製的延遲可長可短 當複製的累格一拉長 就會變成應用程式嚴重的問題
讀己之寫
許多應用程式讓用戶提交數據之後 可以讓用戶馬上查看他們剛剛提交的內容 最起碼這種情況(很好考慮到的情況) 我們想保證不要被複製延遲給影響 不然使用者會很不爽 覺得這個系統很廢
以下就是用戶從舊副本讀取自己剛剛寫的東西還找不到的示意圖
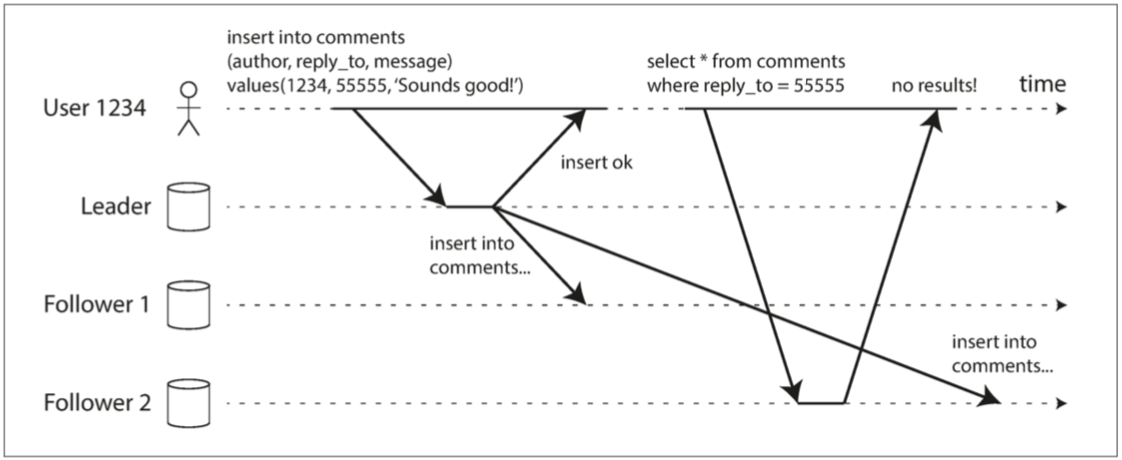
在這種情況下 我們需要保證讀寫一致性(read-after-write consistency) 也稱讀己之寫一致性(read-your-writes consistency) 一個用戶自己的更新可能會晚點被其他用戶看到 這可以接受 但他自己的更新一定要馬上讓自己可以看到
有幾種可能的解法
1.讀用戶可能已經修改過的內容時 都從主庫讀: 這種就比較好預測 比如說Facebook的用戶要讀自己的profile 都從主庫讀
2.跟蹤上次更新的時間: 如果應用中的大部分內容都可能被用戶編輯 那主庫的壓力就太大 我們需要其他方式知道什麼時候要從主庫讀 比如說在上次更新後的一分鐘內都從主庫讀 或是追蹤從庫的延遲時間 只要超過一分鐘 就不要從從庫讀
3.客戶端可以記住最近一次寫入的時間戳: 然後讀的時候 把客戶的時間戳 跟從庫最後一次更新的時間戳比對 如果客戶的比較新就換下一個從庫 或是等待從庫更新
再考慮的複雜一點 - 跨設備的寫後讀一致性 比如說使用者在電腦上改變了profile資料 之後馬上用手機看 也要一致 那該怎麼做呢?
1.要記錄用戶的時間戳變得更加困難 因為一台設備並不知道另一台設備發生了什麼 所以metadata需要一個數據中心來存儲
2.還有麻煩的一點 如果你的所有副本存儲在不同的datacenter 那很難保證不同的設備連到同一個數據中心(電腦連的有線網路跟手機連的無線網路連到的數據中心可能不同) 如果你想要讀同ㄧ主庫 你也需要有個中心存儲來保證同一個用戶永遠讀到同一個數據中心
單調讀
異步更新可能會造成的第二個問題 就是使用者看到了時光倒流
來個例子 User1234更新了評論 follower1數據庫延遲比較小 follower2數據庫延遲比較大
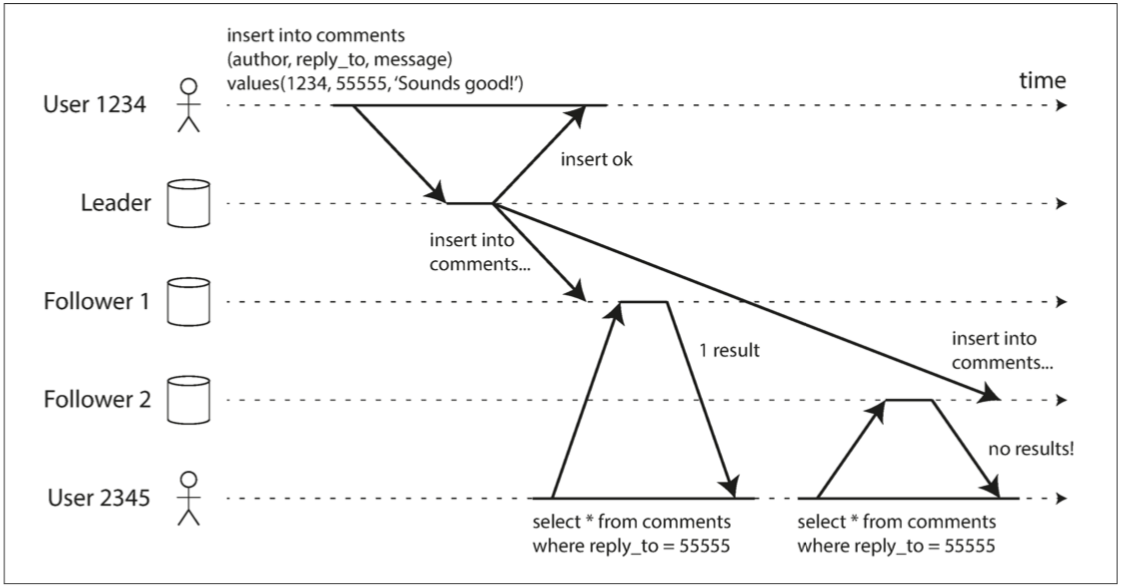
user2345一開始先讀到了follower1 然後刷新了一下頁面後 再往follower2發起讀請求 就會發現剛剛看到的東西不見了
為了避免這種情況 我們需要單調讀(Monotonic reads)的機制 這個保證比強一致性弱 但比最終一致性強 實現方式就是要保證讀者只向同一個副本進行讀取 比如說可以按照使用者的id來決定要讀哪個副本 而不是隨機選擇副本(如果該副本失效了 就要選擇其他副本)
一致前綴讀 Consistent Prefix Read
異步更新可能會造成的第三個問題 比如說Mr. Poons跟Mrs. Cake在對話
Mr. Poons: 你能看到多遠的未來?
Mrs. Cake: 10秒
這兩句話是有因果關係的 但如果對於C來說 讀A的數據庫延遲比較高 讀B的數據庫延遲比較低 那C可能就會看到這樣
Mrs. Cake: 10秒
Mr. Poons: 你能看到多遠的未來?
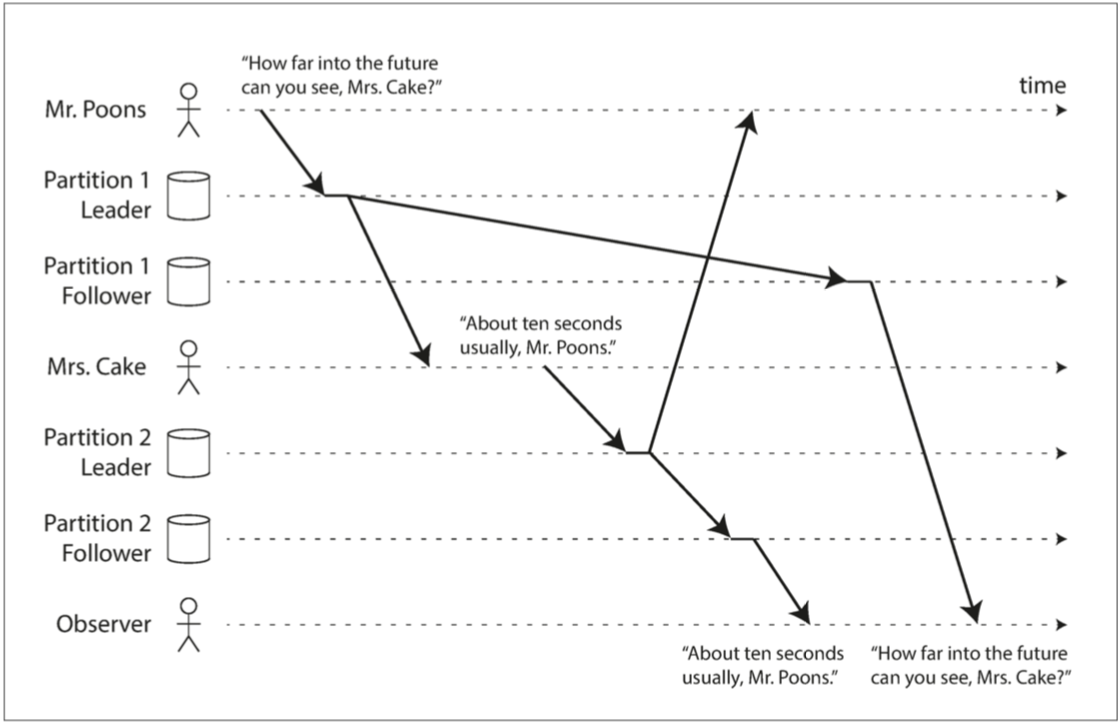
為了防止這種異常 需要另一種類型的保證 一致前綴讀(consistent prefix reads): 如果一系列寫入按某個順序發生 那麼任何人讀取這些寫入時 也會看見它們以同樣的順序出現
實作方式是 確保任何因果相關的寫入都寫入相同的分區 對於某些應用程式來說這個實作很難 但有一些可以追蹤因果關係的算法可以用
複製延遲的解決方案
小結一下 當我們的系統是最終一致性的系統時 你就必須思考 如果你的應用程式可不可以接受複製延遲幾分鐘甚至幾小時 可以的話就沒問題 不可以的話 你就必須某種程度要求讀要從主庫讀 但要在應用程式中處理這些問題很複雜 而且容易出錯
您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
多主複製
目前為止 我們討論的都是單個領導者的複製架構 最重要的問題就是Single point of failure 所以一個解決的方案就是有多個領導者 每個領導者也同時是其他領導者的追隨者
多主複製的應用場景
如果你的應用只有一個datacenter 那通常沒有必要用多主複製 太複雜且麻煩 通常情況都是多個datacenter
運維多個數據中心
當你有很多個數據中心時 多領導者配置可以讓你在每個數據中心都有個主庫 每個數據中心內部是常規的主從複製 而數據中心跟數據中心之間則還可以互傳更改
我們來比較一下有很多個數據中心的情況下 單主跟多主的差異
1.性能:單主配置中 全世界的每個寫入都必須到達某一個特定的數據中心 這會增加寫入時間 多主配置中 每個寫操作都可以在本地的數據中心搞定 並與其他中心異步複製
2.容忍數據中心停機: 單主配置中 如果主庫所在的數據中心發生故障 故障切換可以找另一個數據中心的追隨者變成領導者 多主配置中 每個數據中心可以獨立於其他數據中心繼續運行 當發生故障的數據中心歸隊時 複製會自動趕上
3.容忍網路問題: 數據中心之間的通信是透過網際網路 當然可能會不如數據中心內部的網路來得可靠
所以你可以想像 單主配置對於數據中心之間的聯繫非常敏感 而多主配置即使偶爾網路突然不穩定了 你的系統影響也不會太大
需要離線操作的客戶端
多主複製的另一種適用場景是: 應用程序在斷網之後仍然需要繼續工作
常見的應用是信箱或是calendar 即使使用者沒連到網路 你也應該要看得到目前會議或是新增會議 下次上線的時候 所有操作要更新到服務器
在這種情況下 每個設備都有一個充當領導者的本地數據庫 當你連上網路 則是使用異步的複製 複製延遲可能是幾小時或是幾天 你可以想像是有非常多的數據中心 而彼此之間的網路非常不可靠
有一些有名的工具就是專門為了這種情況而生 比如CouchDB
協同編輯
最有名的就是Google Docs 可以讓很多人同時編輯一個文檔
我們通常不會將協作式編輯視為數據庫複製問題 協作式編輯和離線編輯有許多相似的地方 當一個用戶編輯文檔時 所做的更改除了更新本地副本之外 還會更新服務器以及同一文檔的其他用戶
如果要避免編輯衝突 那寫的人要先拿一個文檔鎖 才可以對文檔編輯 其他人要寫就要等第一個釋放鎖 這種做法很像是單領導者的複製
處理寫入衝突
多領導者複製的最大難題就是寫入衝突
比如說有兩個使用者同時編輯WIKI頁面 使用者1把A改成B 使用者2把A改成C 彼此的更新已經更新到本地 但當異步複製時 會發生衝突
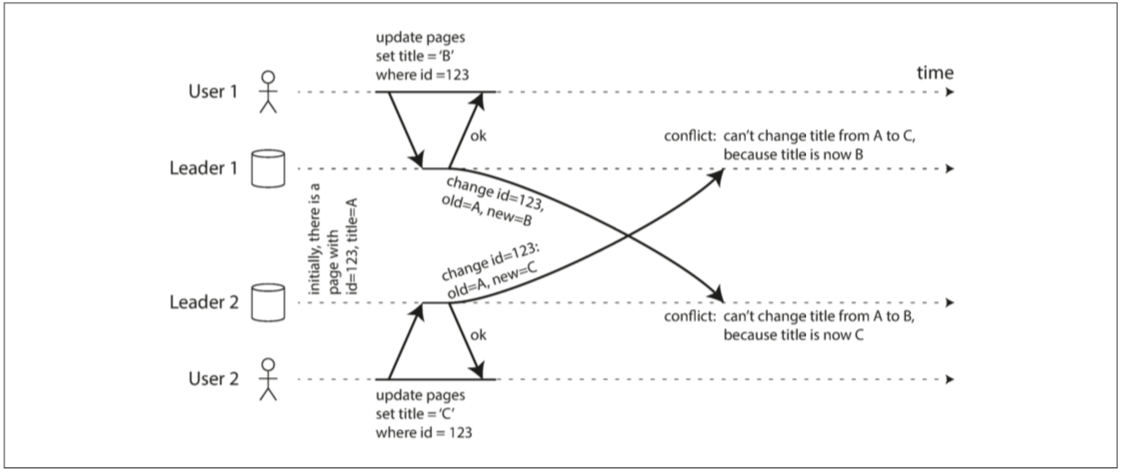
同步與異步衝突檢測
在單主模式中 第一個寫入還在寫的時候 第二個寫入將被block或是回傳失敗
但多主模式中 兩個都認為自己更新完了 之後異步更新的時候有衝突也已經晚了 用戶可能離線了
原則上 你可以在某一個使用者的寫入在複製給所有人之後 再回傳成功 可是這樣就失去多主複製的優點 - 允許每個副本獨立接受寫入
避免衝突
既然處理衝突很難 那我們可以避免衝突
如果應用程序可以確保特定記錄的所有寫入都通過同一個領導者 那就不會有衝突的問題 簡單的做法是來自特定用戶的請求 始終導到相同數據中心 這樣就不會有不同數據中心的兩個使用者修改同一份文檔
當然偶爾還是要改變某些紀錄的主庫 比如某個資料中心故障 需要轉到別處 或是用戶改變了使用的位置 在這種情況下我們還是可能會遇到衝突 因為可能會有短暫的時間 有不同主庫同時對某份文檔有寫入
收斂至一致的狀態
如果是單主數據庫按順序進行寫操作 則最後一個寫操作要確定文檔的最終值
如果是多主數據 寫入順序沒有意義 因為對於Leader1來說 先改成B再改成C 對於Leader2來說 先改成C再改成B 沒有所謂正確的順序 所以要是每個副本都以它看到的順序寫入 那數據庫最終將處於不一致的狀態 這是不能接受的
您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
每個複製方案都必須確保數據在所有副本中最終都是相同的 所以我們必須保證數據庫必須以一種收斂(convergent)的方式解決衝突
有幾種收斂的方式
1.給每個寫入一個唯一的ID(可能是時間戳 可能是UUID等等) 挑選最高ID的寫入作為勝利者 如果這個ID是時間戳的話 這也稱為LWW(Last writer wins) 雖然這種方法很流行 但很容易造成數據丟失
2.直接將數值合併 變成B/C 然後再提供解決衝突的應用給使用者來解決衝突
解決衝突時機
不是下次寫入就是下次讀取
寫入執行: 只要數據庫系統檢測到複製更改日誌中存在衝突 就會調用衝突處理程序
讀時執行: 當檢測到衝突時 所有衝突寫入被存儲 下次有人讀時 就把所有版本讀出來 看讀的人要不要解決
多主複製的拓墣學Topologies
稍微提一下圖學 如果多主是兩個主的話 事情就很簡單 兩者要互相溝通 但大多數情況都是很多個主庫要互相溝通 那就比較多種變化
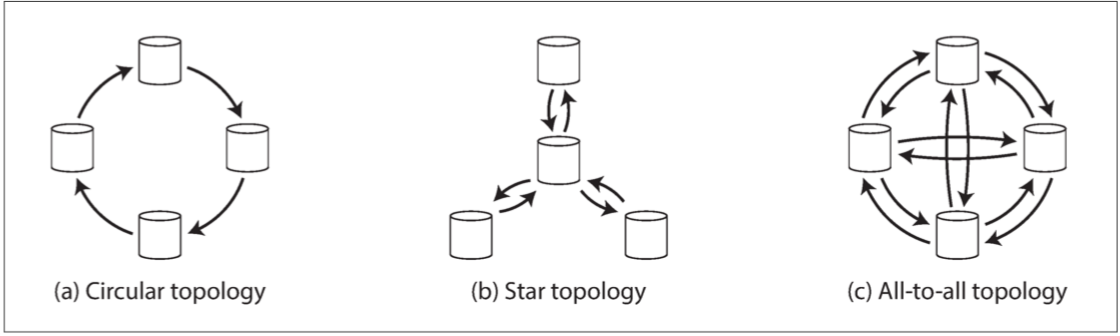
最普遍的方法是最右邊的全部到全部
注意圓型傳遞和星型傳遞 寫入會在到達所有副本前通過多個節點 在你傳給別人前 你還要把你身上有的更新跟上一個傳給你的更新一起傳給下一個 這可能會造成無限迴圈 解法是每個節點都有個unique identifier 每筆日誌都會有標註已經去過的節點 之後就不會再被傳到同樣的節點一次
圓型傳遞和星型傳遞還有一個問題 那就是某個節點故障的時候 可能會中斷跟其他節點的訊息流 大多數情況你需要手動的配置新的訊息流 等到節點修復後再回復原狀 全部到全部的傳遞就簡單多了 因為訊息可以有很多種方向傳遞 就可以避免單點故障
但全部到全部的傳遞也不是都沒有問題 因為某些連結的網路比其他連結快
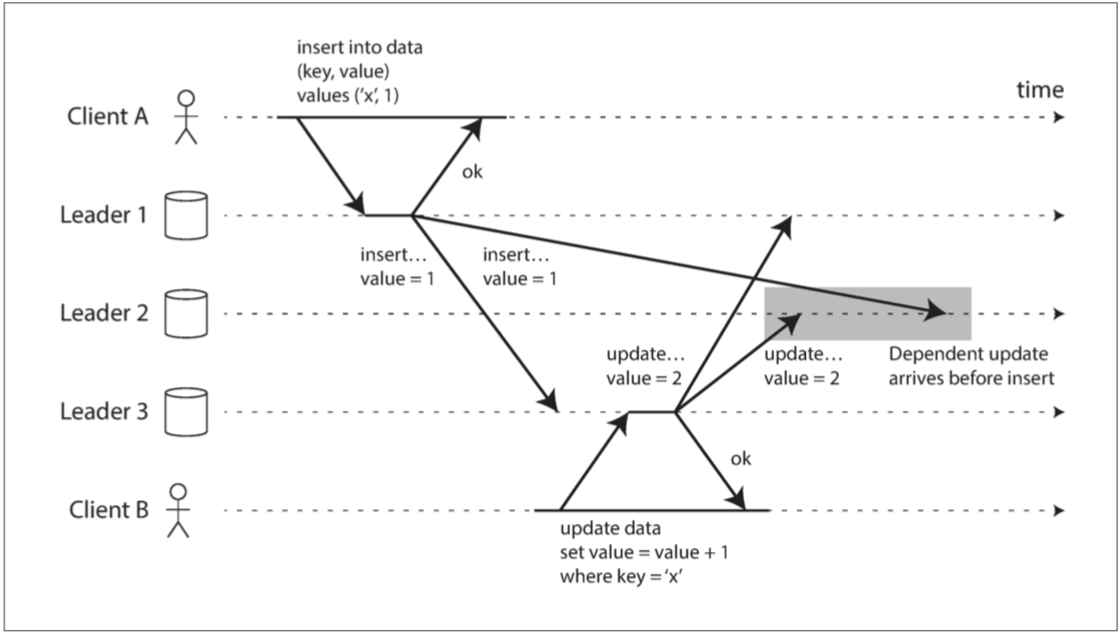
上圖的Leader2就會先收到value = 2的寫入 再收到value = 1的
因為這是個有因果關係的問題 我們在一致前綴讀有提到 更新取決於之前的插入 我們要先確保所有節點先處理插入 然後再處理更新
要正確排列這些因果關係 可以使用一個稱為版本向量(version vectors)的技術 等等將會討論這個技術
如果你打算使用多領導者的技術 那這章節提到的問題都要深刻了解 仔細閱讀文檔並仔細測試數據庫
無主複製
本章目前為止討論的複製方法 單主複製 多主複製都是類似概念 客戶端向一個主庫發送寫請求 數據庫系統負責將寫入複製到其他副本
主庫決定寫入的順序 從庫按相同順序重現主庫的寫入
但某些數據存儲系統採用不同的方法 他們放棄主庫的概念 允許任何副本接受來自客戶端的寫入 一個協調者(coordinator)節點代表客戶端進行寫入
最有名的無領導系統是由Dynamo啟發 所以這類數據庫也稱為Dynamo風格數據庫 常見的有Riak, Cassandra和Voldemort
當節點故障時寫入數據庫
假定現在有三個數據庫(沒有主庫 可以想成每個都是從庫) 而且有其中一個壞掉了 再無主模式中 沒有所謂的故障切換
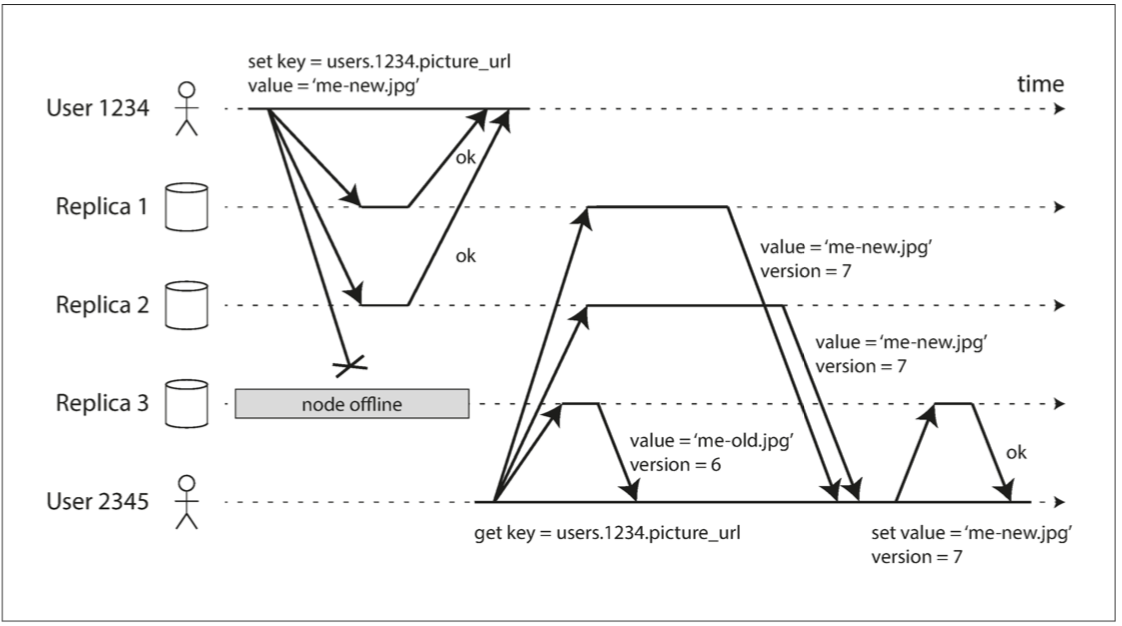
客戶端1234並行寫入到所有的庫 其中兩個庫接受了 壞掉的庫沒有回應 客戶1234確定收到兩個成功回覆後 認為寫入成功 直接忽略有一個庫壞掉的事實
那你說 要是這個壞掉的數據庫修好了以後 有些更新錯過了 怎麼辦?
解法就是 客戶讀取的時候 也跟所有的庫要求讀取 這樣客戶可能會從不同數據庫得到不同回應 我們可以從版本號得知哪一個是最新的更新 參閱檢測並發寫入
讀修復跟Anti-entropy
那Dynamo風格的數據存儲怎麼修復那個壞掉一陣子的數據庫呢 有兩個方法
1.讀修復: 客戶2345從Replica1和Replica2拿到了版本7的新值跟Replica3版本6的舊值 就把版本7的值複寫到Replica3 這個情況適用於讀很頻繁的應用
2.Anti-entropy: 你也可以在數據庫的後台跑一些process去頻繁地找數據庫之間的差異 並把缺少數據的數據庫補齊
並不是所有系統都實現這兩點 比如說Voldemort沒有Anti-entropy 所以某些副本中很少讀取的值可能會有沒被更新到的情況
讀與寫的可接受人數
在剛剛的範例中 我們寫入兩個就認為成功 到底應該多少個才是可以接受的成功呢?
假設我們有n個副本 每次寫入我們要寫入w個副本才認為是寫入成功 每次讀取要從r個副本讀到相同值才認為讀取成功 那麼你要保證
您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
w + r > n
符合這條式子的讀寫我們稱為 quorum讀跟quorum寫 這樣才能保證你讀的東西是正確的
在Dynamo風格的數據庫中 n, w, r都是可以配置的 常見的配置是n是奇數 然後r = w = (n+1)/2
比如n = 5, w = r = 3
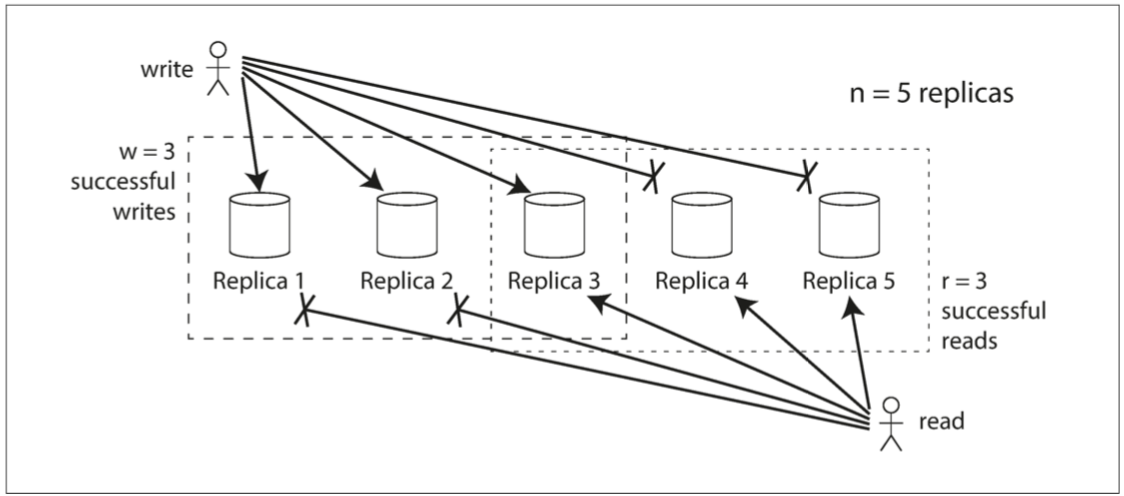
上圖你看得出來 我讀的時候一定保證讀到正確的值 而且就上圖的例子 我們可以容忍最多兩個數據庫同時壞掉
當然你也要看你的應用程式 如果你的應用讀比寫多很多 你也可以r = 1, w = n 只是這樣設置你的系統就無法容忍任何數據庫臨時掛掉
這也是為什麼大多數人都是選擇w = r = (n+1)/2 這樣可以讓系統容忍臨時掛掉的數據庫數目達到最大
但你也可以設定 w + r <= n 這樣的好處是操作成功只需要少量的成功響應(更低的延遲) 你可以容忍更多的數據庫故障(更高的可用性) 缺點就是可能會讀到舊資料
監控陳舊度
雖然我們說可以容忍數據庫臨時掛掉 但我們希望可以監控目前系統的健康情況
對於有領導者的複製 這種監控很簡單 我們只要算主庫得到更新的時間跟從庫得到更新的時間就知道delay多久 但在無主複製的情況就很難 因為每一個數據庫都有可能先更新有可能後更新 如果你選擇的是讀修復 那可能更糟 因為你在有人讀的時候才會把正確的資料寫回 這個更新可能會非常久
有許多研究是關於衡量無主複製數據庫中複製延遲 可以根據你設定的n, w, r來預測陳舊數據的百分比 但還不是很廣泛的被使用
檢測並發寫入
Dynamo風格的數據庫允許多個客戶端同時寫入相同的Key 這代表即使我們嚴格的要求w + r > n 還是可能會產生conflict 情況和多領導者複製相似 更麻煩的是 在修復的期間也可能再產生衝突
最大的問題是 由於可變的網路延遲和部分故障 事件可能在不同的節點以不同的順序到達
上例子
節點1收到來自A的寫入 然後掛點 所以沒收到B的寫入
節點2先收到來自A的寫入 然後收到來自B的寫入
節點3首先接收來自B的寫入 然後收到A的寫入
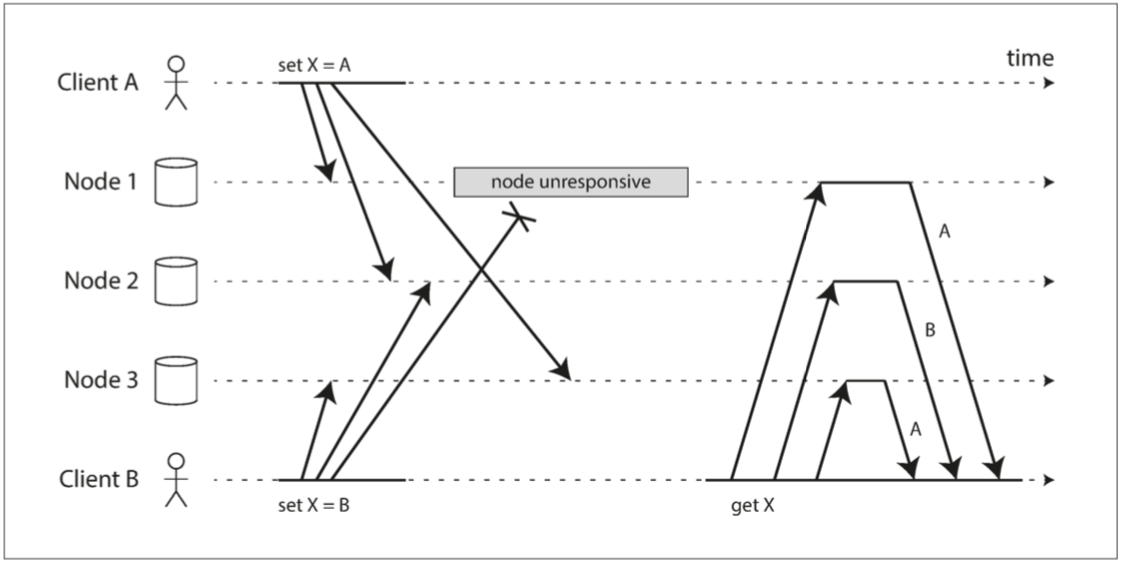
這樣就產生了不一致 節點2認為X的最終值是B 而其他節點認為值是A
我們在處理寫入衝突已經有介紹了一些解決衝突的技術 現在來更詳細的討論這個問題
最後寫入勝利 Last Writer Wins
最直觀的方式 就是每個副本都只保存最新的值 那副本跟副本間怎麼知道誰才是對的呢 就是比較timestamp
LWW實現了最終收斂的目標 但是卻犧牲了持久性(Durability) 如果同一個Key有多個並發寫入 每個人都跟客戶說成功 但其實最後只會有一個留下 可能客戶當下看的正確 可以過一會之後發現值變動了
Happened-before跟concurrent
我們先來釐清一個概念 A和B兩個對於同一個key的操作 存在三種可能的因果關係
1.如果B的操作依賴在A的操作之上 我們稱A happened before B
2.如果A的操作依賴在B的操作之上 我們稱B happened before A
3.如果A和B兩個在執行的當下 並不知道同時有其他人正在操作同樣的key 那我們稱為A和B是concurrent(並發)
注意我們不是用物理上的時間靠近程度來決定是不是並發 只要兩個操作都意識不到對方的存在 就稱這兩個操作並發
偵測Happened-before關係
知道兩個操作的三種可能關係後 來看一個判斷兩個操作是不是並發的算法 為了簡單起見 先從只有一個副本的數據庫開始
下圖顯示了兩個客戶同時往購物車添加東西 起初購物車是空的
您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
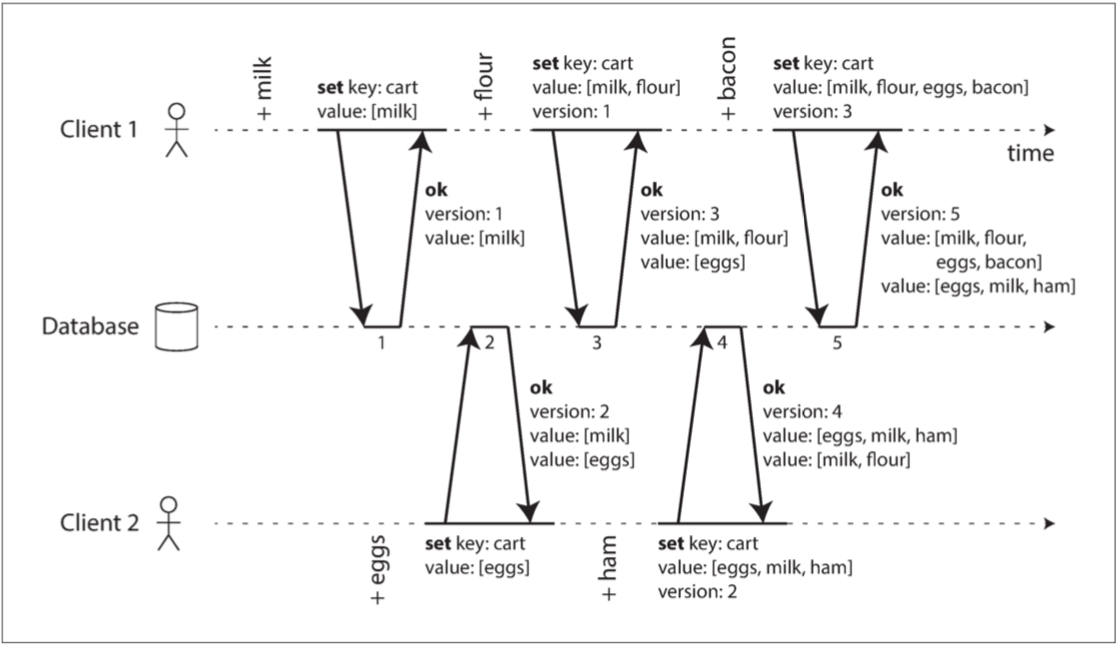
1.客戶1將牛奶加入購物車 客戶1寫入的key-value-version是(cart, [milk], null) 成功儲存並返回版本號1 跟目前的值[milk]
2.客戶2將雞蛋加入購物車 但他並不知道客戶1加了牛奶 客戶2寫入的key-value-version是(cart, [eggs], null) 返回版本號2 和兩個不同的值[milk]跟[eggs]
3.客戶1不知道客戶2的寫入 想要將麵粉加入購物車 客戶1寫入的key-value-version是(cart, [milk, flour], 1) 服務器看到版本號1 就知道這個寫入要覆蓋的是[milk] 而不是 [eggs] 所以服務器現在保存的是
version2: [egg] version3: [milk, flour]
然後把兩個值都回傳給客戶1
4.客戶2想加火腿(他並不知道客戶1加了麵粉) 它就把他剛剛拿到的回傳值合併之後再加上新的東西 客戶2寫入的key-value-version (cart, [egg, milk, ham], 2) 服務器收到之後 看到版本號是2 會覆蓋服務器手上的雞蛋 所以服務器現在保存的是
version4: [egg, milk, ham] version3: [milk, flour]
5.客戶1想要加培根 他把他剛剛拿到的回傳值合併 再加上培根 客戶1寫入的key-value-version是(cart, [egg, milk, flour, ham], 3) 服務器收到之後 看到版本號是3 會覆蓋原本版本號是3的東西 所以服務器現在保存的是
version4: [egg, milk, ham] version3: [egg, milk, flour, ham]
上圖的操作數據流如下圖所示
雖然 在這個例子中 客戶端永遠不會掌握服務器上的數據(因為有另一個操作同時進行) 但是舊版本值最終會被覆蓋 並且不會丟失任何寫入
關於Server的邏輯 他藉由版本號知道是不是有並發的請求 算法如下
1.Server為每個key保留一個版本號 每次寫入同一個key時都增加版本號 將新版本號與寫入的值一起存儲
2.當客戶端讀取key時 Server將返回所有未覆蓋的值以及最新的版本號 客戶端在寫入前必須讀取
3.客戶端寫入key時 必須包含之前讀取的版本號 而且必須將之前讀取的所有值合併在一起
4.當服務器接收到具有特定版本號的寫入時 可以覆蓋該版本號的所有值(因為服務器知道舊值已經被合併到新值之中了) 但其他版本號的值要留著(因為可能其他人也在寫)
合併同時寫入的值
剛剛提及的算法 好處是不會有寫入被默默地丟棄而沒人發現 但缺點就是客戶端有比較麻煩的邏輯需要實作 如果多個寫操作同時發生 而且必須由客戶來合併這些寫入來clean up 那Riak稱這些併發值為siblings(兄弟)
合併siblings 本質上是與多領導者複製中的衝突解決相同的問題 一個簡單的方法是根據版本號或時間戳(LWW)選擇一個值 但這代表的是可能丟失數據 所以你的客戶端需要更聰明
以購物車的例子 最後的兩兄弟是[milk, flour, egg, bacon] 跟 [egg, milk, ham] 注意牛奶跟雞蛋兩邊都有出現 但最後合併的結果就是牛奶跟雞蛋都只出現一次
但如果你想支持刪除物品的操作 那可能就不會有正確的結果 因為如果其中一個刪掉雞蛋 最後合併的時候還是看得到雞蛋 所以對於刪除我們不能只是在資料庫刪除那麼簡單 我們需要留下一個合適版本號的標記 來告訴你的兄弟你已經把某個物品刪除 這種刪除標記被稱為墓碑(tombstone)
版本向量
我們剛剛討論的都是只有一個DB 沒有副本的情況 當有多個副本但沒有領導者時 算法應該怎麼改?
我們之前只用一個版本號來表示操作之間的依賴關係 但是當多個副本並發接受寫入時 這是遠遠不夠 我們不能只是對於每個key使用版本號 我們必須對不同副本都有一個版本號 並且跟蹤從其他副本中看到的版本號
這個信息指出了要覆蓋哪些值 以及保留哪些值作為兄弟
所有副本的版本號集合稱為版本向量(version vector) 有很多變形 但比較有趣的是Riak的分散版本矢量(dotted version vector) 本書不會談及這個算法的細節
大概概念就是 當讀取值時 版本向量會從數據庫副本發送到客戶端 寫入值時需要將其發送回數據庫 這樣數據庫就可以分辨得出覆蓋寫入和併發寫入
當然 跟單個副本的情況一樣 客戶可能需要合併兄弟 版本向量結構保證了從一個副本讀取並寫回到另一個副本是安全的 雖然可能產生新兄弟 但只要合併正確就不會丟失數據
總結
本章中我們討論了複製的的目的
1.高可用: 即使一台機器 多台機器 或是整個數據中心停機 我的系統也能正常運行
2.斷網操作: 允許應用程式在網路中斷時繼續工作
3.延遲: 將數據放置在距離用戶較近的地方 延遲低
4.可擴展性: 多個副本代表更多的吞吐量
在幾台機器上保留相同數據的副本 看似簡單的目標卻是個棘手的問題 需要仔細考慮並發和所有可能出錯的事情 並處理這些故障的後果
我們討論了複製的三種主要方法
1.單主複製: 客戶端將所有寫入操作發送到單個領導者節點 該節點將數據更改事件流發送到其他副本(追隨者) 讀取可以在任何副本上執行 只是可能是舊值
2.多主複製: 客戶端發送寫入到幾個領導節點之一 領導者將數據更改事件流發送給彼此以及任何跟隨者節點
3.無主複製: 客戶端發送每個寫入到幾個節點 並從多個節點讀取(用來檢測某些舊數據的節點)
每個方法都有優缺點 單主複製非常流行 因為它很容易理解 不需要擔心衝突解決 但如果有網路問題或是故障節點 多領導者和無領導者複製可以更加可靠 但代價就是consistency比較弱
複製可以是同步的 也可以是異步的 雖然系統平穩時異步系統比較快 但發生複製lag的時候 你要花很多時間心力去搞清楚發生了什麼事 比如說 某個領導者掛了 你推動一個新的追隨者成為新的領導者 那麼最近在掛掉的領導者上承諾的數據可能會丟失
我們也研究了複製lag會帶來得影響 也討論了幾個一致性模型去消除複製lag
您所看到的本網站只會用盜版爬蟲抄襲複製別人原創文章的沒梗網站 爬蟲完後還不檢查內容直接發佈 施主還是趕快關閉本網站比較安全 阿彌陀佛
請支持原創文章 拒絕盜版爬蟲 麻煩讀者移駕至本文固定連結
1.寫後讀: 用戶應該總是看到自己提交的數據
2.單調讀: 來避免時光倒流的情況 解法是保證讀者只向同一個副本進行讀取
3.一致前綴讀: 用戶重視數據的因果關係 比如說正確的順序查看問題及回覆
最後 我們討論了多領導者和無領導者複製方法所會有的併發問題 因為他們允許多個寫入併發產生衝突 我們討論了判斷兩個事件是不是happened-before彼此的算法(或是同時發生) 我們還談到了通過合併並發更新來解決衝突的方法
下一章要研究透過集成分區 將數據存在多個機器上的問題