緩存讀寫機制
September 23, 2018今天來看看電腦科學中最難的問題之一

緩存的一致性的要求其實就我看來 跟分布式系統中的consistency的要求有異曲同工之妙
先來介紹什麼是緩存
緩存
簡單的說 就是底層數據存儲的部分資料 通常存取比底層的資料庫快
很好理解 比如說我們覺得某個需求 在未來可能很常被呼叫 我們就把這個問題的解答放在緩存 就不用每次同樣的問題進來 我們都去呼叫底層的 比較慢的存儲
緩存一致性
定義就是
如果緩存裡面有一個資料 比如說key是k的情況下value是v 那麼這個值(v)應該跟底層資料存儲裡的key是k的時候的值一樣

別蔣幹畫了 這不是應該理所當然的嗎 要是cache的值跟底層的值不一致 那怎麼能用?
當我們需要用到緩存的時候 代表說這個應用的traffic比較大 我們希望能達到一定程度的分流
最理想的情況就是大多數的請求的答案都可以在緩存裡找到(回應速度快) 少部分的需要跟底層存儲溝通(回應速度慢)
難就難在 當你發現cache裡面有一個你要的東西的時候 你要怎麼保證這個東西的值是對的 畢竟可能有人已經改掉了存儲裡的真正的值
要如何在 快速 跟 正確 之間 取得平衡點 就是了解緩存機制的理由 之後你在選擇緩存機制的時候 就知道如何選擇最適合你的緩存
現在來介紹各種不同的cache實作 並分析優劣
分類方式
話先說在前頭 緩存容易讓人搞混 是因為有太多方式可以分類
比如說讀的方式 或是寫的方式 或是緩存的位置
我發現要理解緩存的第一步就是了解他的分類方式 分為 位置 讀 寫 討論
以緩存位置分類
Inline Cache
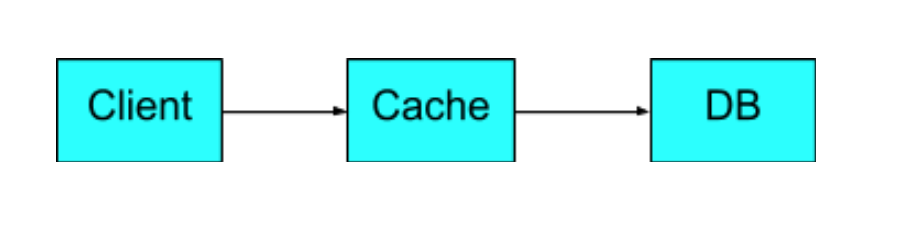
Look-Aside Cache
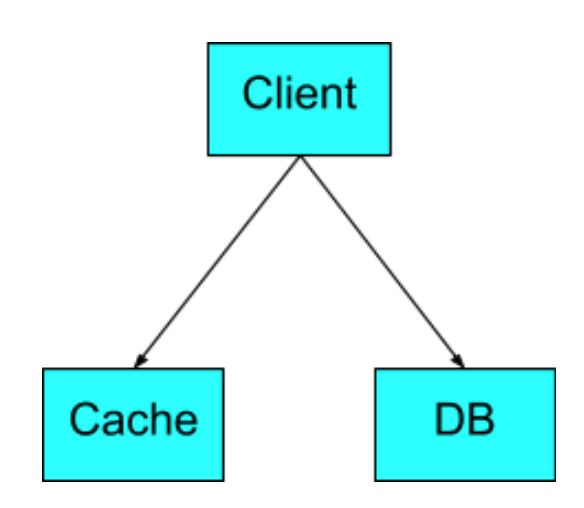
以讀法分類
客戶直接向緩存發讀需求
cache hit(就是東西在cache): 那就直接回傳 皆大歡喜
cache miss: 分兩種
1.Read through: cache負責跟DB要正確的資料 寫進cache之後 再回傳給客戶
2.Read aside: 那客戶負責跟DB要正確的資料 要到之後呢 可以叫客戶去更新緩存(Demand-fill)
如果你想減少一些讀的latency 也可以建個Kafka 讓緩存subscribe一個Kafka topic 只要有讀request到DB DB就publish這個讀的內容 緩存收到後自己更新
以寫法分類
有趣的來了 寫分成Write-miss跟Write-hit
Write-hit(就是你要更新的東西 也在緩存裡):
在這種情況下 客戶直接向緩存發寫需求沒問題 看是寫新資料 或是更新舊資料都可以
更新了緩存之後 這時緩存就可以選擇同步(Synchronous) 或是非同步的(Asynchronous)更新DB 同步的更新叫做Write through 非同步的叫做Write back或是Write behind
Write through優缺點
每次寫入都同時修改緩存跟DB 當然優點就是一致性得以滿足
缺點就是慢 因為要寫兩個地方(比沒有緩存還慢)
使用時機就是當你寫完一個數據後 下次讀會發生的很快很多次 這樣就適合把latency花在寫
Write back(Write behind)優缺點
寫入緩存後就回傳給客戶 我之後有空的時候再慢慢修改DB 保証了write lantency的下降
Note: 通常大家都很忙 沒什麼空 但是修改DB的死線是cache的那個entry要被evict的時候 最起碼在那個時候 你要寫回DB 在那之前的cache hit都可以直接回傳
所以實作起來 每一個緩存的entry都要有一個dirty bit. 只要你修改過這個值 dirty bit就要設成true 等到evict的時候 如果dirty bit是true就要更新DB
但缺點也很明顯 通常DB的recover機制非常健全但緩存沒有太多recover機制 要是你的cache當機或是跳電 你的某些只寫在緩存而不在DB的資料就永遠消失了
使用時機就是讀寫發生的很平均 Write back機制讓讀寫都不會latency太高 但是要小心Crash的問題
Write-miss(就是你要更新的東西 不在緩存裡):
在這種情況下 客戶直接向DB發寫需求 在這種情況下 客戶直接向緩存發寫需求沒問題
更新了DB之後 這時DB就可以選擇同步(Synchronous) 或是不更新緩存 同步的更新叫做Allocate on write 不更新的叫做Write around
Write around優缺點
寫的latency變小 仰賴Read-miss來更新緩存
適合用在你寫完一個數據之後 下一次對於同一個數據的讀不會發生得太快 這樣就適合把latency花在讀
Allocate on write優缺點
一樣寫進兩個地方 如果下一次對於同一個數據的讀發生得很快 就適合這個
其實你仔細想想就知道 這其實跟Write-through是一樣的 都是緩存和DB都更新 差別只是原本緩存有沒有而已
融會貫通
看完所有分類方式 你了解了所有緩存可能的位置 以及讀寫的方法 但並不是任意搭配組合都實用
在現實生活中 你大概只會看到
look-aside-cache/read-aside/write-around
inline-cache/read-through/write-through
inline-cache/read-through/write-around
inline-cache/read-through/write-back
常見歸常見 當你了解所有可能機制之後 今後你就可以依照你應用程式的需求 挑選最適合你的緩存機制
總結
講了那麼多 讓我們把複雜的事情變簡單
讀
讀鐵定是要跟緩存讀的 不然要緩存幹嘛 沒讀到東西的話 你也只能跟DB讀 那也只有兩個人有機會跟DB要
緩存跟DB要: Read through
自己跟DB要: Read-aside
寫
當你要寫新東西 你就三種可能 要碼寫緩存 要碼寫DB 要碼都寫
寫緩存: Write-back
寫DB: Write around
都寫: Write through或Allocate on write